프로메테우스를 이용하여 쿠버네티스 환경 metric 수집하고 모니터링하기
이전에 저는 컨테이너가 아닌 일반적인 레거시 운영 환경에서 Glances + Influxdb + Grafana 스택의 모니터링 시스템을 구축하고 사용했습니다. glance로 서버 성능 데이터를 수집하고 influxdb라는 시계열 데이터베이스(TSDB)에 저장한 다음 Grafana를 이용하여 화면에 뿌려주는 방식으로 Dashboard를 구현했죠. glance는 python 기반의 시스템 성능 모니터링 도구로 주로 LoadAvg, bps 단위의 네트워크 트래픽, Disk I/O, 메모리 사용율 등 정보를 확인할 수 있습니다. 하지만 도커와 쿠버네티스 등 컨테이너 기반 운영 환경에서 보다 다양한 메트릭을 수집하는데엔 프로메테우스가 가장 적합하다고 할 수 있습니다.
이번 포스팅에서는 프로메테우스의 장점에 대해 살펴보고, 프로메테우스를 이용하여 쿠버네티스 환경에서 애플리케이션과 시스템 메트릭을 수집하고 모니터링하는 방법에 대해 다뤄보겠습니다.
Prometheus
메트릭(Metric) : 시간이 흐르면서 변화하는 수치화된 측정값을 의미
프로메테우스는 쿠버네티스 클러스터와 같은 대상으로부터 측정값을 수집하고 저장하는 도구입니다. CNCF에서 관리하는 프로젝트인 만큼 쿠버네티스와 가장 궁합이 좋은 메트릭 수집도구죠. 프로메테우스는 쿠버네티스 클러스터의 노드와 파드 뿐만 아니라 서비스, 엔드포인트, 인그레스와 같은 가상의 컴포넌트의 메트릭도 수집할 수 있다는 장점이 있습니다. 그리고 이전에 Influxdb를 별도로 설치하여 사용했던 것과 달리 프로메테우스는 자체적으로 포함된 시계열 데이터베이스에 수집한 메트릭을 저장할 수 있습니다.
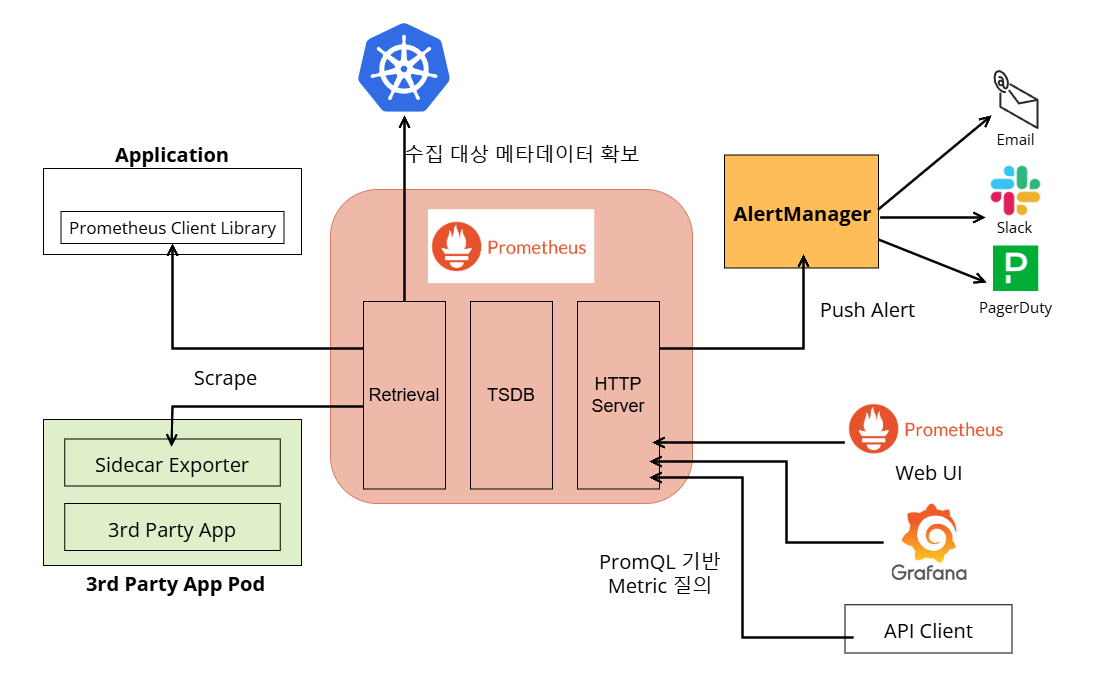
애플리케이션을 개발할 수 있는 대부분의 프로그래밍 언어는 프로메테우스 클라이언트 라이브러리를 지원하는데요. 이 라이브러리를 사용하여 애플리케이션을 빌드하면 런타임 내 메모리, CPU 사용량과 스레드 수 등 측정값을 수집할 수 있습니다. 혹은 nginx나 PostgreSQL 같은 서드 파티 애플리케이션의 경우 프로메테우스에 측정값을 노출할 수 있는 추출기(Exporter)를 사이드카 패턴으로 사용할 수 있습니다.
프로메테우스는 수집한 메트릭을 자체 TSDB에 저장합니다. 프로메테우스 웹 서버와 이후에 소개할 Grafana, 프로메테우스 API 클라이언트는 저장된 데이터를 PromQL(Prometheus Query Language) 로 질의하여 확인할 수 있죠. 그리고 AlertManager에 경보를 Push하여 이메일이나 Slack, PagerDuty를 통해 알림이 전송되도록 할 수 있습니다.
Helm을 사용하여 프로메테우스를 설치할 수 있지만 어떤 포트로 서비스를 하고 API 서버를 통해 메타데이터를 가져오기 위해 어떤 권한을 부여해야 하는지 등을 직접 체험해보기 위해 매니페스트를 작성하여 배치해 보기로 했습니다.
apiVersion: v1
kind: ServiceAccount
metadata:
name: prometheus
namespace: monitoring
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus
labels:
app: monitoring
rules:
- apiGroups: [""]
resources:
# 노드와 서비스, 엔드포인트, 파드 메타데이터만 접근
- nodes
- services
- endpoints
- pods
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources:
- configmaps
verbs: ["get"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: prometheus
labels:
app: monitoring
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus
subjects:
- kind: ServiceAccount
name: prometheus
namespace: monitoring
monitoring이라는 네임스페이스가 이미 생성되어 있다는 전제 하에, 먼저 서비스 계정과 RBAC를 먼저 살펴보겠습니다. Clusterrole은 노드와 서비스, 엔드포인트, 파드에 대한 메타데이터를 가져올 수 있도록 했는데요. 필요에 따라 리소스에 인그레스도 추가할 수 있지만 현재 별도의 인그레스가 배치되어 있지 않기 때문에 제외했습니다. 이처럼 프로메테우스가 꼭 메타데이터를 가져와야 하는 리소스에만 접근할 수 있도록 최소 권한을 설정해 주는 것이 좋습니다.
apiVersion: v1
kind: Service
metadata:
name: prometheus
namespace: monitoring
spec:
selector:
app: prometheus
type: NodePort # 웹 페이지 확인을 위한 NodePort 설정
ports:
- port: 9090
targetPort: 9090
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus
namespace: monitoring
spec:
selector:
matchLabels:
app: prometheus
template:
metadata:
labels:
app: prometheus
spec:
serviceAccountName: prometheus
containers:
- name: prometheus
image: prom/prometheus:v3.2.1
args:
- "--config.file=/config/prometheus.yml"
- "--web.enable-lifecycle" # 설정 변경 시 자동 적용
ports:
- containerPort: 9090
volumeMounts:
- name: prometheus-config
mountPath: /config/
volumes:
- name: prometheus-config
configMap:
name: prometheus-config
서비스와 디플로이먼트입니다. 프로메테우스는 주로 9090 포트로 서비스하는데요. 웹 UI를 로컬에서 확인할 수 있도록 NodePort로 열어주겠습니다.
--web.enable-lifecycle 는 프로메테우스 설정을 변경하면 재기동 없이 reload할 수 있도록 지원하는 Argument 입니다. 이 Argument를 추가하면 SIGHUP signal 혹은 /-/reload path로의 HTTP POST 요청을 통해 설정을 다시 읽어들일 수 있습니다. 변경된 애플리케이션 설정값을 반영하기 위해 다시 rollout을 하는 것이 꽤나 신중함이 필요한 일인데요. 프로메테우스는 HTTP 메소드 호출을 통해 설정값 반영이 가능하다는 점이 편리하게 다가옵니다.
프로메테우스 configuration
프로메테우스에서는 Job(잡)을 정의할 수 있고, 메트릭을 Scrape(스크랩)하고 Relabeling(리레이블링)할 수 있습니다. 프로메테우스는 규칙들을 Label(레이블)을 기준으로 처리합니다.
-
Scrape - 메트릭 수집을 의미
-
Job - 서로 연관된 수집 대상의 집합을 정의 (e.g. 같은 애플리케이션을 구성하는 컴포넌트 집합)
-
Label - 메트릭의 출처와 기타 정보를 담은 Key=Value 쌍
-
Relabeling - 수집한 메트릭을 취합하고 저장할 메트릭을 선별하고 가공하는 과정
컨피그맵 형태로 배치한 prometheus.yml 파일의 구성을 살펴보도록 하겠습니다.
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: monitoring
data:
prometheus.yml: |-
global:
scrape_interval: 30s # 수집 대상에서 메트릭을 스크랩하는 주기
scrape_configs: # 스크래핑 규칙 정의
- job_name: 'pods in test namespace' # 잡 이름
kubernetes_sd_configs: # 쿠버네티스 API 서버를 통해 수집 대상을 찾는다
- role: pod # 파드를 대상으로 수집
relabel_configs: # 리레이블링 규칙 정의
- source_labels:
- __meta_kubernetes_namespace # 네임스페이스 메타데이터를 저장하는 레이블
action: keep # 레이블을 그대로 유지
regex: test # 'test' 네임스페이스일 경우
-
source_labels: 리레이블링에 활용할 기존의 레이블들을 정의 -
target_label: 선별하여 가공한 값을 새로 저장할 레이블 정의 -
action: 레이블을 어떻게 처리할 것인가 (기본값 : replace) -
regex: 레이블의 value에서 추출할 패턴에 대한 정규표현식 (각 레이블에 ‘;’로 구분하여 적용)
리레이블링은 마치 FluentD나 Logstash에서 Input된 로그를 Parsing하고 Filtering하는 파이프라인과 비슷한 개념입니다. 여기서는 쿠버네티스 API 서버를 통해 메타데이터를 얻어 레이블에 저장하고, 이를 기반으로 테스트 네임스페이스 내 파드의 메트릭을 스크래핑한다는 규칙을 확인할 수 있습니다.
- source_labels:
# 파드에 prometheus.io/scrape라는 annotation이 있는가?
- __meta_kubernetes_pod_annotationpresent_prometheus_io_scrape
# 해당 annotation의 값
- __meta_kubernetes_pod_annotation_prometheus_io_scrape
regex: true;false # 각각 값이 true, false와 일치할 경우
action: drop # 스크래핑하지 않는다
-
__meta_kubernetes_pod_annotationpresent_<annotation name>: 해당 annotation이 파드 정의에 존재하는지 확인하는 레이블 -
__meta_kubernetes_pod_annotation_<annotation name>: 해당 annotation의 값을 저장하는 레이블
위의 레이블들을 이용하여 특정 애플리케이션을 스크래핑에서 제외할 수 있습니다. 이 설정은 애플리케이션 파드에 prometheus.io/scrape 라는 annotation이 있는지 확인하고 값이 false일 경우 스크래핑하지 않도록 하는 규칙입니다.
# prometheus.io/path annotation을 가졌을 경우 annotation의 값을 메트릭 수집 경로로 지정
- source_labels:
- __meta_kubernetes_pod_annotationpresent_prometheus_io_path
- __meta_kubernetes_pod_annotation_prometheus_io_path
regex: true;(.*)
target_label: __metrics_path__
- source_labels:
- __meta_kubernetes_pod_annotationpresent_prometheus_io_target
- __meta_kubernetes_pod_annotation_prometheus_io_target
regex: true;(.*)
target_label: __param_target
- source_labels:
# prometheus.io/port annotation을 가졌으면 __address__에서 포트 번호를 제거하고 새로운 포트 번호로 접근
- __meta_kubernetes_pod_annotationpresent_prometheus_io_port
- __address__
- __meta_kubernetes_pod_annotation_prometheus_io_port
# 레이블별로 true, __address__ 레이블의 값에서 포트 번호 제외, annotation에서 제공하는 포트 번호 추출
regex: true;([^:]+)(?::\d+)?;(\d+)
replacement: $1:$2 # host:지정 포트 형태로 교체
target_label: __address__
__metrics_path__: GET 요청을 보내 메트릭을 수집할 HTTP sub 경로를 저장하는 레이블 (기본값 : /metrics)__param_<name>: 가장 먼저 전달되는 URL 파라미터를 저장하기 위한 파라미터 설정__address__: 수집 대상의 주소를 저장하는 레이블, 주로 host:port 형태
첫번째 리레이블링 규칙에서는 prometheus.io/path 라는 annotation을 가진 파드를 대상으로 annotation의 값을 __metrics_path__ 타겟 레이블로 리레이블링하여 해당 값(경로)으로 메트릭을 스크래핑 하도록 한다는 규칙을 보여주고 있습니다.
두번째는 prometheus.io/target 이라는 annotation을 가진 파드를 대상으로 annotation의 값을 target이라고 하는 파라미터에 저장한다는 규칙입니다. 주로 URL 파라미터를 저장하고 활용하는데 쓰입니다.
세번째는 __address__에 대상에 접근할 포트 번호를 바꾸기 위한 규칙입니다. 프로메테우스는 기본값으로 80번(http) 포트로 접근하여 대상을 스크래핑하는데 만약 대상이 다른 포트로 메트릭을 노출한다면 해당 포트 번호로 접근해야 할 수 있어야 합니다. 그래서 기존 __address__ 레이블의 값에서 :80을 제외하고 annotation에서 제공하는 포트 번호를 붙인 URL로 리레이블링하는 규칙입니다. 주로 별도로 지정된 포트로 메트릭을 노출하는 추출기 사이드카 패턴을 사용하는 애플리케이션에 적용하기 위한 규칙입니다.
# app으로 시작하는 파드 레이블이 있을 경우 잡 이름으로 지정
- source_labels:
- __meta_kubernetes_pod_labelpresent_app
- __meta_kubernetes_pod_label_app
regex: true;(.*)
target_label: job
# 파드 이름을 instance 레이블에 저장
- source_labels:
- __meta_kubernetes_pod_name
target_label: instance
-
__meta_kubernetes_pod_labelpresent_<label name>: 해당 파드 레이블이 있는지 확인하는 레이블 -
__meta_kubernetes_pod_label_<label name>: 해당 파드 레이블의 값을 저장하는 레이블 -
job: 리레이블링 잡 이름을 저장하는 레이블 (기본값 : scrape_configs에서 지정한 job_name) -
__meta_kubernetes_pod_name: 파드 이름을 저장하는 레이블 -
instance: 모든 리레이블링이 끝나고 난 후 설정되는 레이블로 주로 수집 대상을 지칭하는 이름을 저장 (기본값 :__address__)
파드 레이블을 기준으로 잡을 정의하고 싶을 때 사용할 수 있는 규칙입니다. 그리고 수집 대상을 지칭하는 레이블인 instance에 기본값인 URL이 아닌 파드 이름을 저장하여 가독성을 높일 수 있습니다.
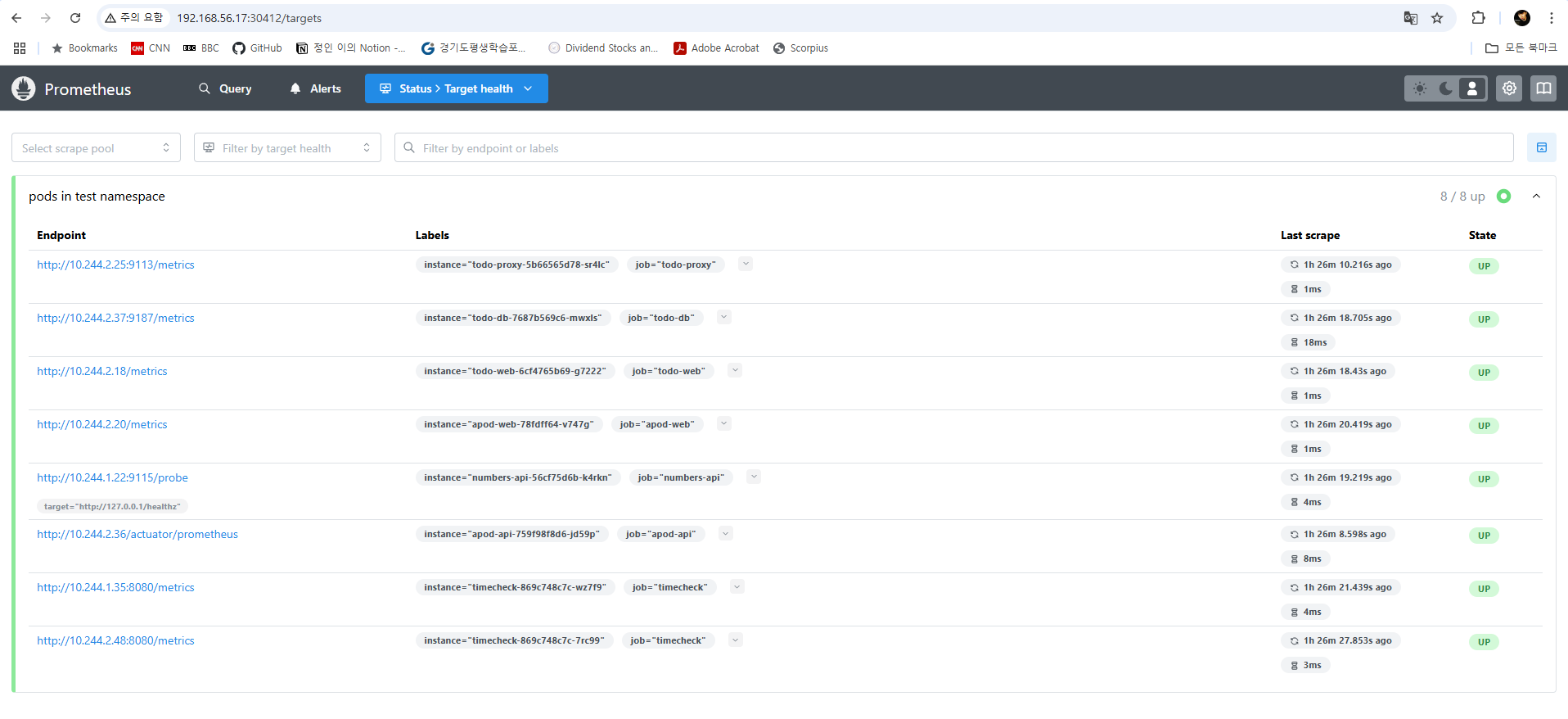
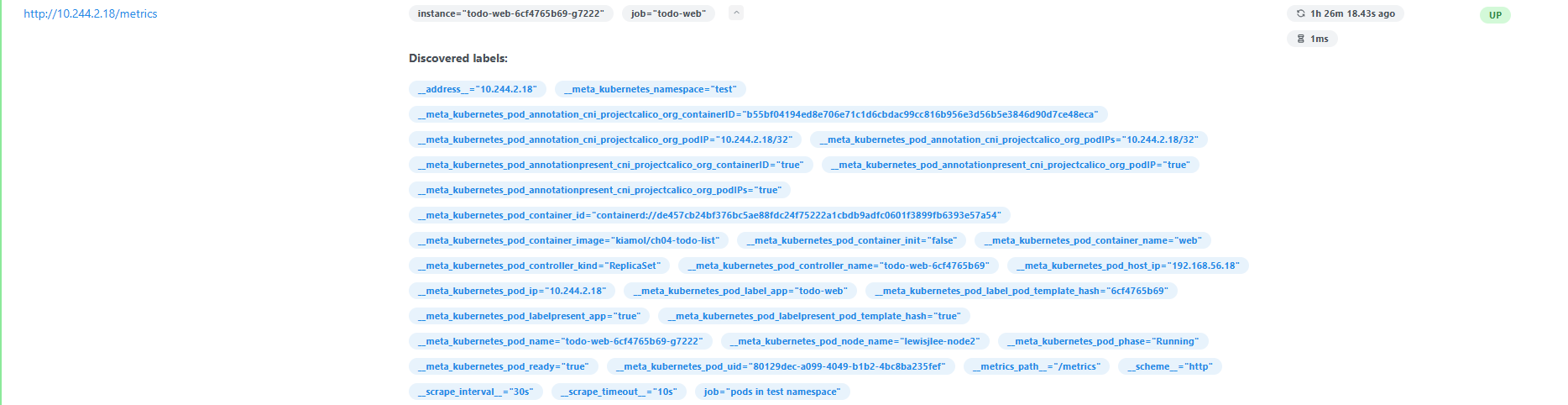
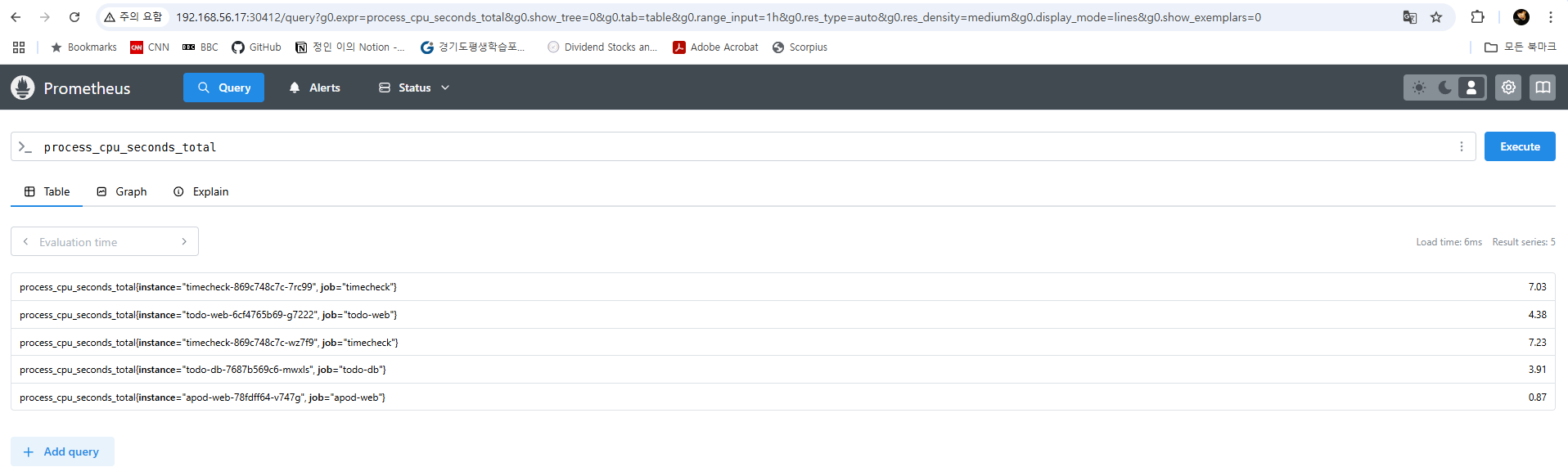
이제 프로메테우스 웹 UI를 확인해보겠습니다. /target 페이지에서는 잡 이름과 수집 대상의 엔드포인트, 기본적인 레이블들과 리레이블링된 레이블들을 확인할 수 있습니다. 그리고 /query 페이지에서는 쿼리를 실행하여 수집된 메트릭 데이터를 확인할 수 있습니다. 이처럼 prometheus.yml에 규칙을 정의하고 규칙에 부합하는 수집 대상의 메타데이터를 레이블에 저장하고 메트릭을 스크래핑할 수 있습니다.
프로메테우스를 이용한 중앙화된 애플리케이션 모니터링 시스템을 구축하기 위해서는 개발팀과 운영팀이 서로 긴밀한 협업이 필요합니다. 핵심적인 상세 지표를 모니터링할 수 있는 고도화된 시스템을 만들기 위해서는 어느 정도 개발 공수가 들 수 있는데요. 하지만 기본적인 메트릭부터 시작해서 점차 필요한 지표를 차근차근 추가하는 방식으로 모니터링 시스템을 개발해 나갈 수 있습니다. 어떻게 보면 이것 또한 일종의 애자일(Agile) 방식으로 진행할 수 있다고 생각됩니다.
Node-exporter를 이용한 노드 메트릭 스크래핑
애플리케이션 뿐만 아니라 클러스터를 구성하는 노드의 성능도 모니터링할 수 있어야 하는데요. 이를 위해서 Node-exporter를 사용할 수 있습니다. 노드 익스포터는 각 노드의 성능 메트릭을 노출하는 도구입니다. 리눅스 버전과 윈도우 버전 모두 지원하므로 OS에 맞는 버전을 선택하여 설치할 수 있죠.
노드 당 하나씩 배치되어야 하므로 데몬셋으로 설치하고 prometheus.yml에도 새로운 잡을 추가해 주도록 하겠습니다.
apiVersion: apps/v1
kind: Daemonset
metadata:
name: node-exporter
namespace: monitoring
spec:
selector:
matchLabels:
app: node-exporter
template:
metadata:
labels:
app: node-exporter
spec:
tolerations:
- key: node-role.kubernetes.io/control-plane
operator: Exists
effect: NoSchedule
containers:
- name: node-exporter
image: prom/node-exporter:v1.9.0
ports:
- containerPort: 9100
- job_name: 'node-exporter'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels:
- __meta_kubernetes_namespace
- __meta_kubernetes_pod_name
regex: monitoring;node-exporter-\w+
action: keep
- source_labels:
- __meta_kubernetes_pod_node_name
target_label: instance
컨트롤 플레인 또한 모니터링 대상이기 때문에 데몬셋 정의에 toleration을 추가해 주었습니다.
모니터링 네임스페이스에 배치되고 파드 이름이 노드 익스포터로 시작하는 대상의 레이블을 그대로 유지하고, 파드가 배치된 노드 이름을 instance로 리레이블링하여 어떤 노드의 메트릭인지 쉽게 알아볼 수 있도록 규칙을 설정해 주었습니다.
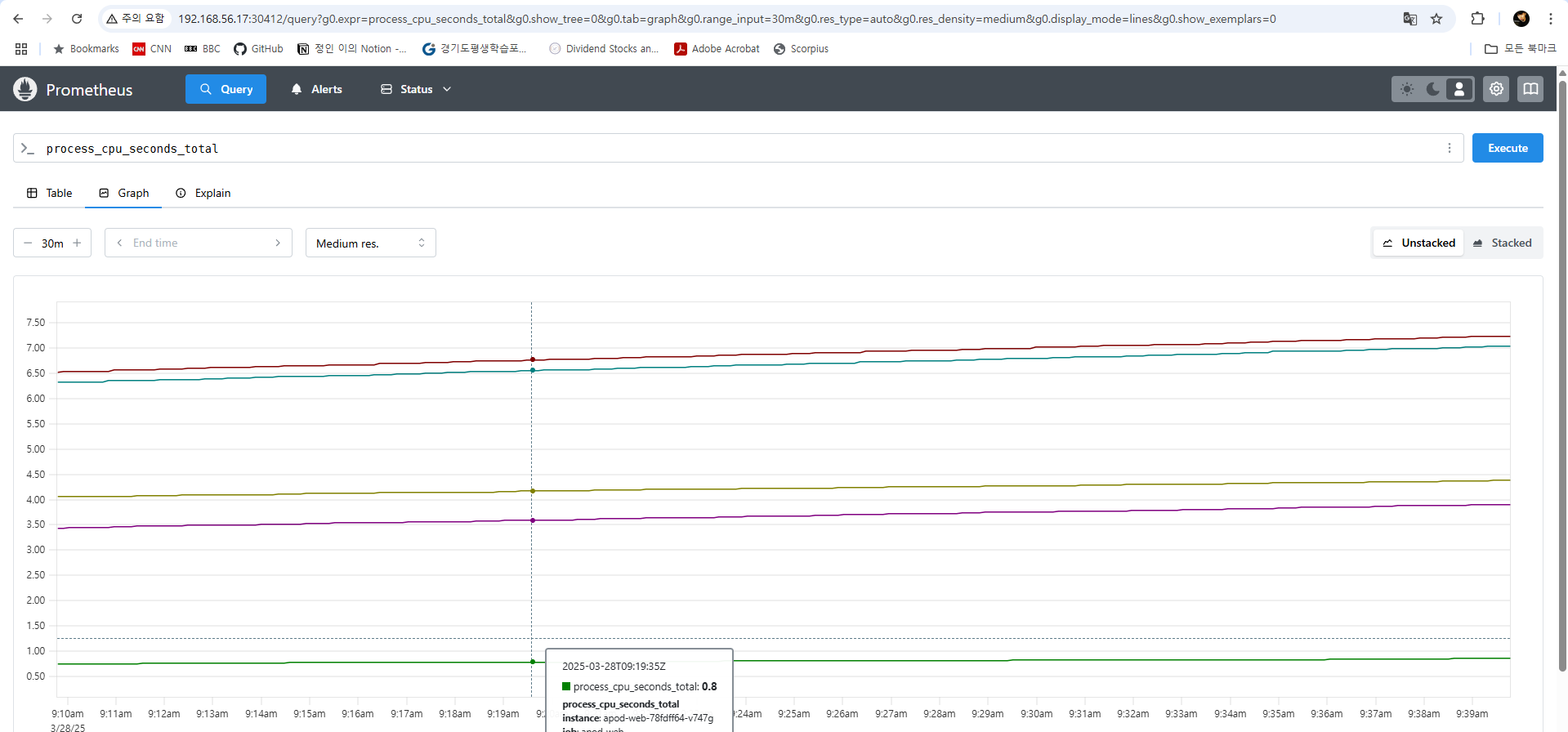
노드 익스포터는 node_로 시작하는 많은 다양한 메트릭들을 노출하는데 노드의 CPU 사용량과 Disk I/O, 네트워크 트래픽 등의 정보를 수집할 수 있습니다. 이전에 사용했던 glance와 비슷한데요. 노드 익스포터는 프로메테우스에서 함께 사용하길 권장하는 도구이니만큼 프로메테우스 스택을 사용하여 시스템을 모니터링하려고 한다면 꼭 함께 도입해볼 수 있겠습니다.
kube-state-metrics
프로메테우스는 API 서버를 통해 쿠버네티스 클러스터의 메타데이터를 얻어올 순 있지만 객체에 대한 상태 정보는 가져올 수 없습니다. 이 때 kube-state-metrics라는 컴포넌트를 배치하면 이러한 상태 정보 메트릭들을 수집할 수 있죠. kube-state-metrics는 쿠버네티스 클러스터의 개별 컴포넌트보단 kube_로 시작하는 파드, 노드, 디플로이먼트, 컨피그맵 등 쿠버네티스에서 지원하는 다양한 객체의 상태 메트릭을 가져오는 데 중점을 두고 있습니다.
kube-state-metrics는 공식 github에서 helm 차트나 개별 매니페스트로 설치할 수 있습니다.
- job_name: 'kube-state-metrics'
static_configs:
- targets: # kube-state-metrics 서비스에 직접 접근하여 메트릭 수집
- kube-state-metrics.kube-system.svc.cluster.local:8080
- kube-state-metrics.kube-system.svc.cluster.local:8081
위의 프로메테우스 설정이 다른 수집 대상과는 조금 다른 것을 확인할 수 있는데요. kube-state-metrics 자체가 유용한 쿠버네티스 객체 메트릭을 노출하기 때문에 쿠버네티스 API 서버로부터 수집 대상을 찾지 않고 kube-state-metrics에 직접 접근하여 메트릭을 스크래핑하는 설정입니다.

cAdvisor
cAdvisor는 파드 내 컨테이너의 메트릭을 수집할 수 있는 도구입니다. 원래 kubelet에는 cAdvisor가 포함되지만 보안 문제로 특정 쿠버네티스 버전에서부터 kubelet 내장 cAdvisor에 대한 접근 엔드포인트를 지원하지 않게 되었습니다. 그래서 프로메테우스가 파드 내 컨테이너의 메트릭을 수집하기 위해서는 별도의 cAdvisor를 설치해야 하죠.
cAdvisor 역시 공식 github를 참고하여 데몬셋으로 설치할 수 있습니다.
- job_name: 'cadvisor'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels:
- __meta_kubernetes_namespace
- __meta_kubernetes_pod_labelpresent_name
- __meta_kubernetes_pod_label_name
action: keep
regex: cadvisor;true;cadvisor
위와 같이 cadvisor 파드에서 메트릭을 스크래핑하는 설정을 추가해 줍니다.

Grafana
그라파나는 애플리케이션의 주요 지표와 성능을 모니터링할 수 있는 UI를 제공하는 대시보드 OSS입니다. ELK/EFK Stack에서 Kibana가 하는 역할과 비슷하죠.
그라파나의 장점은 설치하고 난 후 UI에서 직접 Data Source를 선택하고 대시보드를 구성할 수 있다는 것입니다. 그라파나 디플로이먼트와 서비스를 배치하고 톺아보도록 하겠습니다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: grafana
namespace: monitoring
spec:
selector:
matchLabels:
app: grafana
template:
metadata:
labels:
app: grafana
spec:
containers:
- image: grafana/grafana:11.6.0-ubuntu
name: grafana
ports:
- containerPort: 3000
name: grafana
envFrom:
- secretRef:
name: grafana-secret
apiVersion: v1
kind: Service
metadata:
name: grafana
namespace: monitoring
spec:
selector:
app: grafana
ports:
- name: grafana
port: 3000
targetPort: 3000
type: NodePort
apiVersion: v1
kind: Secret
metadata:
name: grafana-secret
namespace: monitoring
type: Opaque
stringData:
GF_SECURITY_ADMIN_USER: "admin"
GF_SECURITY_ADMIN_PASSWORD: "p@ssW0rd!@#$"
GF_USERS_DEFAULT_THEME: "light"
컨테이너 이미지는 가상 환경의 OS인 Ubuntu에 맞는 것을 사용하고 초기 관리자 계정과 비밀번호, UI 테마에 대한 환경변수를 secret을 통해 그라파나 파드에 주입하도록 했습니다.
그라파나에서 생성한 대시보드는 /var/lib/grafana/dashboards 하위에 JSON 파일로 저장되는데요. 여기서는 별도의 영구 볼륨을 사용하진 않았지만 대시보드 JSON 파일 보관을 위해 영구 볼륨을 해당 path에 mount해주는 것도 좋은 방법입니다. 혹은 UI에서 직접 JSON을 다운로드할 수 있습니다.
그라파나를 배치하고 초기 로그인을 하면 Data Source를 설정해 주어야 하는데, 공식 문서에서 참고한 대로 홈 탭 > Connection > Data sources에 들어가 프로메테우스를 손쉽게 추가할 수 있습니다.
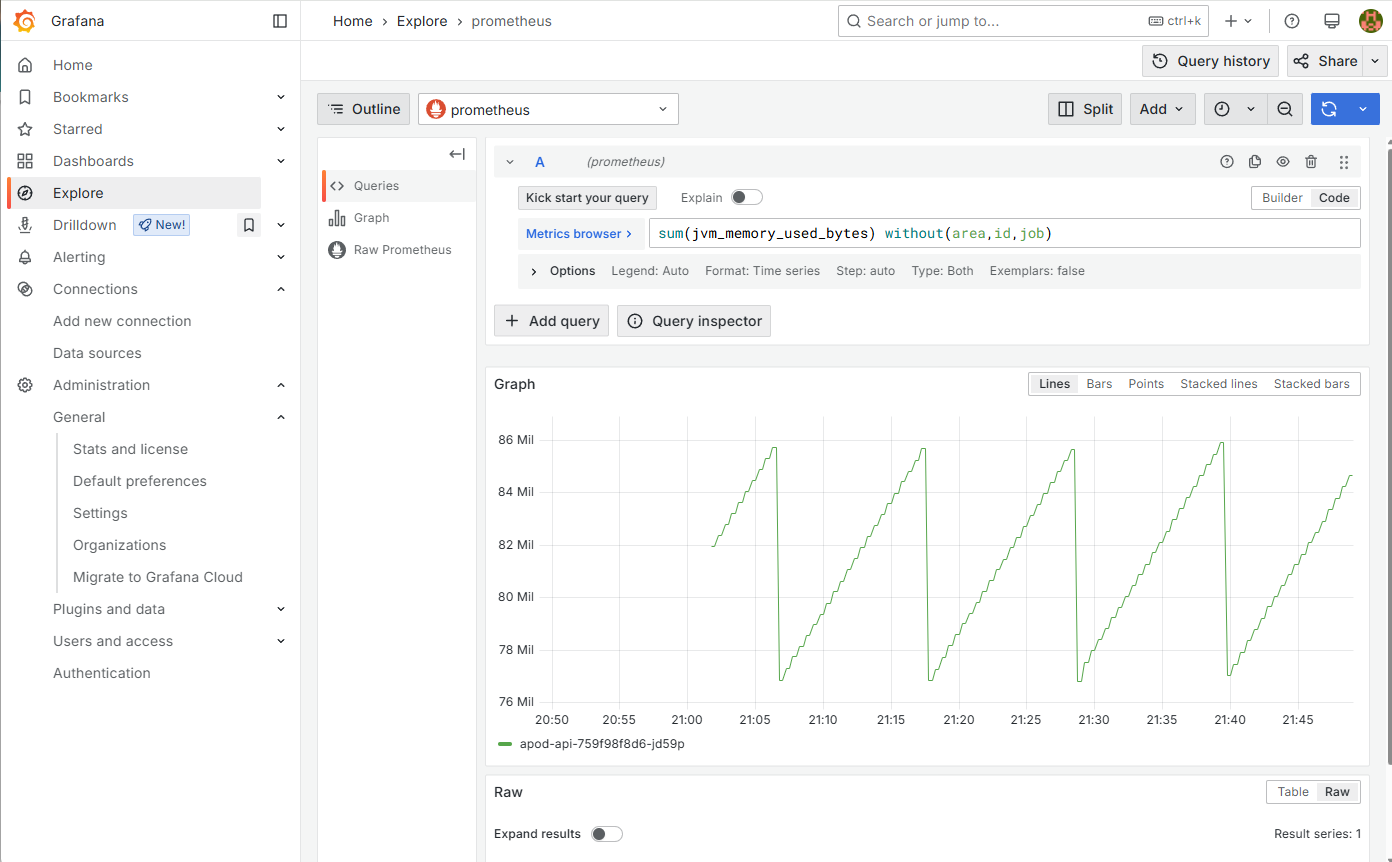
그리고 Explore 메뉴에서는 프로메테우스가 스크래핑하는 메트릭을 바탕으로 쿼리를 작성하여 테스트할 수 있습니다. 앞서 이야기한 것처럼 그라파나는 프로메테우스 자체 TSDB에 PromQL로 질의하는데요. 아래 이미지와 같이 쿼리를 작성하여 그래프로 결과를 확인할 수 있습니다.
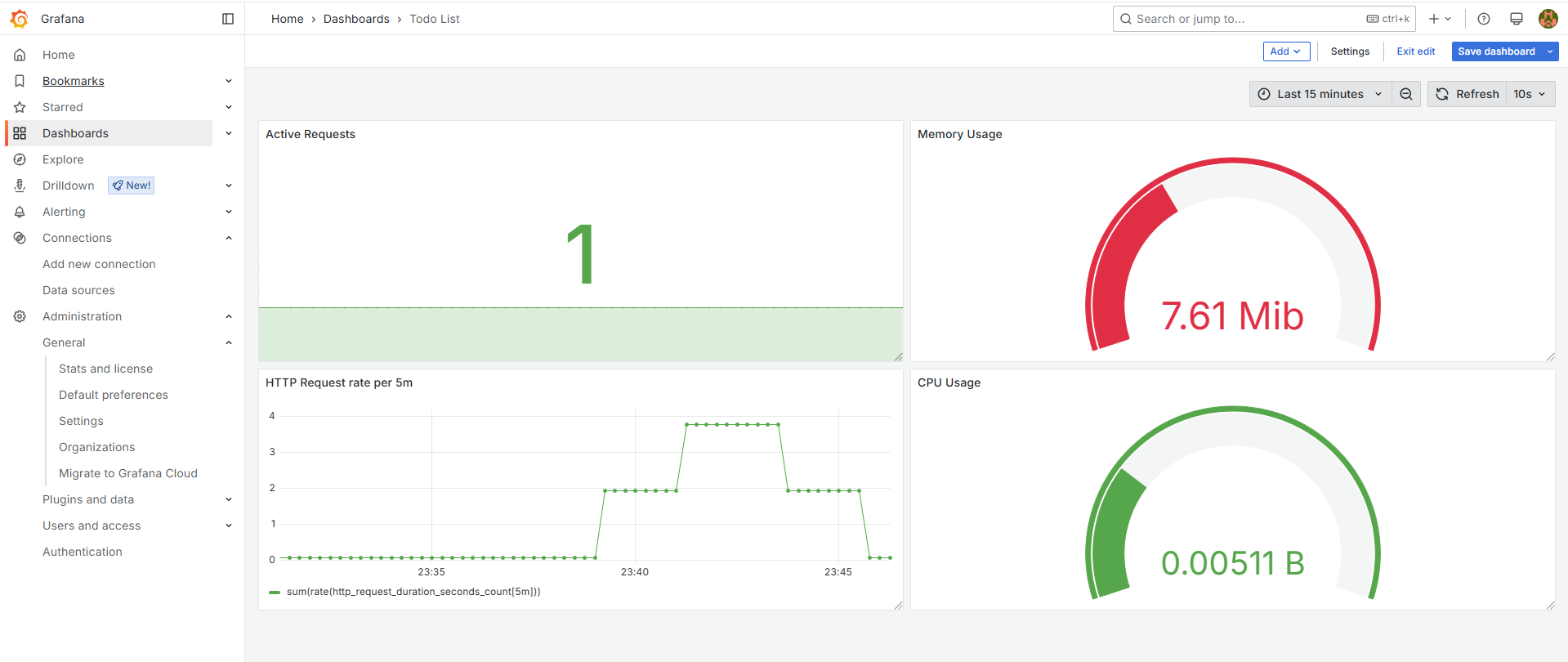
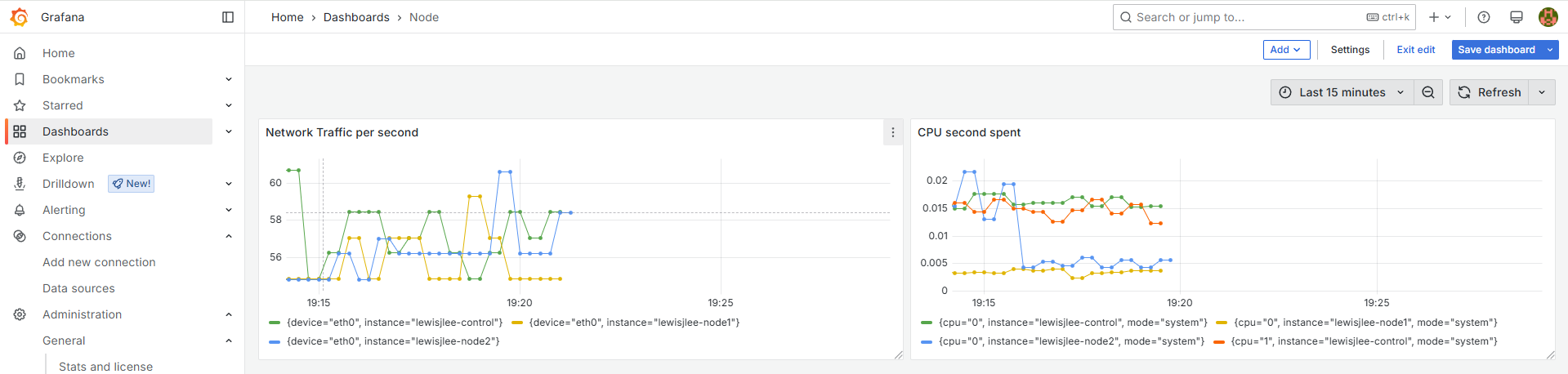
테스트를 마치면 Dashboard 메뉴에서 새로운 대시보드를 생성하고 visualization이라는 그래프를 생성하여 적용할 수 있습니다. 하나의 Dashboard에 여러 개의 visualization이라는 그래프를 포함하는 형태로 그래프는 Time Series, Gauge, Stat 등 다양한 유형을 선택할 수 있습니다.
혹은 그라파나 공식 사이트에서는 다양한 환경의 예제 대시보드를 제공하므로 json을 다운받아서 config에 적용하거나 ID를 그라파나 UI에서 Import하여 대시보드를 즉시 생성할 수 있습니다.
InfluxDB vs Prometheus
제가 이전에 레거시 인프라를 모니터링하는데 InfluxDB를 사용했다고 이야기했는데요. 이번 포스팅에서 소개한 프로메테우스와 비교해보면 어떨까요?
지금까지 살펴본 바로는 InfluxDB는 시계열 데이터베이스의 역할을 하는데 그치는 반면, 프로메테우스는 직접 메트릭을 스크래핑하고 자체 TSDB에 저장한 다음 UI에서 수집 상태를 직접 확인할 수 있다는 점에서 모든 필요한 기능을 올인원으로 갖춘 도구로 여겨집니다. InfluxDB를 사용할 경우 메트릭 수집기나 추출기가 직접 데이터를 밀어줘야 하는 것으로 알고있는데요. 실제로 저도 glance에서 InfluxDB URL을 지정해서 데이터를 밀어줘야 했던 것으로 기억합니다. 그래서인지 Prometheus가 굉장히 경쟁력 있는 도구라는 인상을 느꼈습니다.
가장 눈에 띄는 차별화 포인트는 최적화된 쿼리 모델입니다. InfluxDB의 쿼리인 InfluxQL은 일반적인 RDB의 SQL과 굉장히 흡사한 반면, 프로메테우스의 PromQL은 앞서 살펴본 것처럼 함수 형태로 간결하게 되어 있어 작성과 실행이 편리하죠. 이러한 점에서 프로메테우스는 훨씬 강력한 쿼리 언어를 사용한다고 소개하고 있고 경보와 알림 기능성에도 최적화되어 있다고 소개합니다.
아키텍쳐와 스토리지 구조에서도 차이가 있는데요. 프로메테우스는 본래의 기능에 충실하기 위해 각 서버에 독립적으로 설치되어 로컬 스토리지에만 의존하는 반면, Commercial(상업적인 목적으로 배포되는) InfluxDB는 샤딩 기능을 제공하여 분산 스토리지를 기반으로 수평 확장이 가능하고 트랜잭션을 병렬로 처리할 수 있습니다.
즉 요약하자면 먼저 InfluxDB와 프로메테우스는 각각 Tag와 Label이라는 다차원적 메트릭 처리를 지원하는 key=value 형태의 데이터 모델을 갖는다는 공통점이 있습니다. 하지만 InfluxDB는 이벤트 로깅에 주 목적을 두고 수집한 데이터를 비교적 오래 보관하기에 좋은 클러스터 기능(샤딩 및 분산 스토리지)을 Commercial 버전에서 사용할 수 있고, 프로메테우스는 성능 메트릭 모니터링에 주 목적을 두고 빠른 처리와 시각화, 알림 기능에 최적화된 완전한 오픈 소스 도구라는 차이점이 있습니다.
프로메테우스 최적화
프로메테우스를 통해 대량의 메트릭을 수집하고 처리하다 보면 그 자체만으로 높은 부하를 일으킬 수 있기 때문에 더욱 효율적인 시각화를 위한 PromQL 튜닝과 메트릭 노출 최적화가 필요할 수 있습니다. 저는 작년 SLASH24에서 소개한 7일 동안의 max_over_time을 계산하는 쿼리를 튜닝한 사례와 메트릭 Aggregation 도구를 개발하여 프로메테우스의 메트릭 스크래핑에 대한 부담을 줄인 사례를 통해 유용한 인사이트를 얻을 수 있었습니다.
장기간 내 최대치를 산정하는 그래프를 구성할 경우 시간 단위를 쪼개서 함수를 중첩하는 방식을 사용하는 등 쿼리를 튜닝하여 프로메테우스와 그라파나에 가해지는 부하를 줄일 수 있습니다. 그리고 프로메테우스 UI에서 제공하는 TSDB Status 메뉴를 통해 시스템 자원을 많이 사용하는 레이블과 메트릭을 발견하고 불필요한 것들을 제거하거나 통합하는 방식으로 Cardinality를 줄여볼 수 있습니다. 메트릭 Aggregation 도구를 직접 개발하는 것의 경우 팀 규모에 따라 다르겠지만 많은 공수가 들 수 있기 때문에 해보면 좋다 정도로만 남기는 게 좋을 것 같네요.
끝으로 주기적으로 Release되는 새로운 버전을 빠르게 적용하는 것도 좋은 모범 사례가 될 수 있습니다. 프로메테우스는 오픈 소스이기 때문에 TSDB나 API, Storage Buffer 등의 성능을 효율화한 신규 버전이 자주 출시되는데요. 이러한 오픈 소스 도구들을 지속적으로 업그레이드하는 것만으로도 시스템 자원 사용량을 훨씬 절감할 수 있습니다.
References
Elton Stoneman. (2021). 쿠버네티스 교과서. 길벗출판사
Monitoring Linux host metrics with the Node Exporter
GitHub - kubernetes/kube-state-metrics: Add-on agent to generate and expose cluster-level metrics.
댓글남기기