EFK와 ELK Stack으로 중앙화된 log 모니터링 체험하기
모든 서비스 애플리케이션은 운영 history를 남기기 위해 log를 쌓도록 되어 있습니다. 로그는 주로 서버에서 생성되고 특정 스토리지 공간에 보관되다가 logrotate와 같은 프로세스로 오래된 로그를 삭제하는 방식으로 관리되는데요. 하지만 수십 대 이상의 서버로 구성된 운영 환경에서 문제가 발생했을 때 서버 한 대씩 접속해서 로그를 확인하는 식으로 추적하는 방식은 대응을 상당 시간 지연시킬 수 있습니다.
가독성 높은 format으로 로그를 잘 생성하고 삭제하는 것도 중요하지만, 로그를 적절한 곳에 보관하고 손쉽게 확인할 수 있도록 하는 것도 중요합니다. 따라서 노드에 관계없이 이슈를 쉽게 확인할 수 있도록 로그 모니터링을 중앙화 할 수 있는 도구들이 실제 SRE 환경에서 많이 사용되는데요.
이번 포스팅에서는 대표적으로 사용되는 EFK와 ELK Stack을 쿠버네티스 기반으로 직접 구성해보고 중앙화된 로그 모니터링을 체험해 본 경험에 대해 작성해 보려고 합니다.
Log 처리 Pipeline 구성
EFK와 ELK Stack은 애플리케이션 컴포넌트로부터 로그를 수집하고 데이터베이스에 보관하여 UI에 출력하는 형식으로 파이프라인이 구성됩니다. 여기서 EFK는 Elasticsearch + FluentD + Kibana로 구성되는 파이프라인을 의미하고, ELK는 Elasticsearch + Logstash + Kibana로 구성되는 파이프라인을 의미하는데요. 로그 수집기를 FluentD와 Logstash중 어떤 것을 선택하느냐의 차이로 두 개의 Stack으로 나뉘게 됩니다.
Elasticsearch
Elasticsearch는 강력한 검색 엔진 기능을 갖춘 Document 기반 데이터베이스 입니다. 고정된 스키마를 갖지 않는 형태인 도큐먼트 단위로 데이터를 저장하며, RDBMS에서 데이터베이스에 상응하는 인덱스(Index) 라는 곳에 저장합니다. 엘라스틱서치는 RESTful 기반 데이터베이스로 데이터에 대한 CRUD(Create, Read, Update, Delete)를 HTTP Method로 처리할 수 있고, 공유 스토리지를 사용하는 여러 개의 노드로 구성된 클러스터로 실행하거나 AWS의 Opensearch같은 Public Cloud 관리형 서비스로 사용할 수도 있습니다.
Kibana
엘라스틱서치와 같이 Elastic사에서 개발하여 호환성과 레퍼런스 측면에서 유리하기 때문에 엘라스틱서치 기반 시각화 도구는 대부분 Kibana가 사용되는데요. KQL(Kibana Query Language) 를 사용하여 데이터를 엘라스틱서치에 질의하며, 최종적으로 엔지니어가 로그를 확인할 수 있는 Frontend로 사용됩니다.
EFK
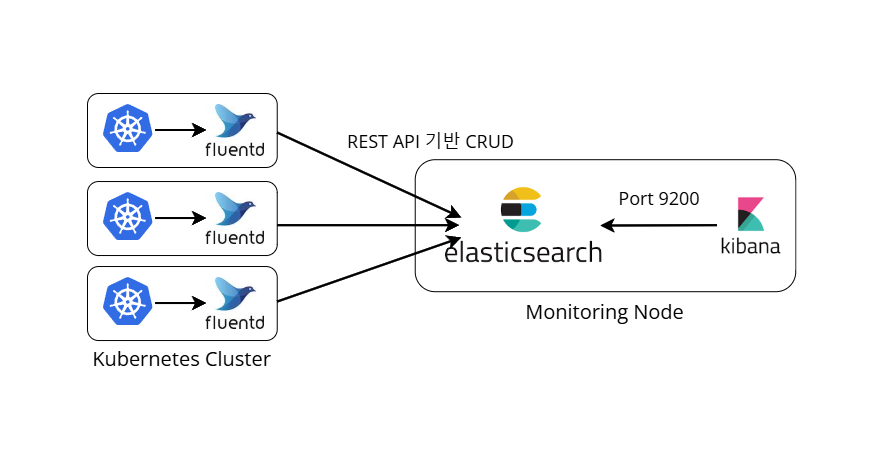
최소 버전의 경량화 로그 수집기 Fluent-Bit
FluentD는 CNCF 재단에서 개발한 로그 수집기로 1000가지 이상의 다양한 출력 대상 플러그인을 지원하는데요. 저는 FluentD의 최소 버전으로 알려진 Fluent-Bit를 사용하여 구성해 봤습니다.
Fluent-Bit는 Daemonset으로 실행하여 각 노드에 파드를 하나씩 배치해서 로그를 수집하고, 애플리케이션 로그 뿐만 아니라 노드의 시스템 로그 또한 수집하고 처리할 수 있습니다.
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluent-bit
namespace: logging
labels:
app: sre
spec:
selector:
matchLabels:
app: fluent-bit
template:
metadata:
labels:
app: fluent-bit
spec:
ServiceAccountName: log-collector
containers:
- name: fluent-bit
image: fluent/fluent-bit
volumeMounts:
- name: fluent-bit-config
mountPath: /fluent-bit/etc/
- name: log-dir
mountPath: /var/log
- name: containers-dir
mountPath: /var/lib/docker/containers
readOnly: true
volumes:
- name: fluent-bit-config
ConfigMap:
name: fluent-bit-config
- name: log-dir
hostPath:
path: /var/log
- name: containers-dir
hostPath:
path: /var/lib/docker/containers
플루언트 비트는 쿠버네티스 환경을 위한 내장 필터 기능이 있어 로그에 파드와 네임스페이스 정보 메타데이터를 태그로 추가할 수 있는데요. 이를 위해서는 쿠버네티스 API 서버를 호출할 수 있는 권한이 필요하기 때문에 ServiceAccount와 적절한 RBAC가 부여되어야 합니다.
apiVersion: v1
kind: ServiceAccount
metadata:
name: log-collector
namespace: logging
labels:
app: sre
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: log-collector
labels:
app: sre
rules:
- apiGroups: [""]
# 파드 및 네임스페이스 정보 접근 권한
resources:
- namespaces
- pods
verbs: ["get", "list", "watch"]
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: fluent-bit
labels:
app: sre
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: log-collector
subjects:
- kind: ServiceAccount
name: log-collector
namespace: logging
Fluent-Bit Configuration
다음은 플루언트 비트에 주입할 설정 파일 ConfigMap입니다. 플루언트 비트는 로그 수집 및 처리 과정을 INPUT->PARSER->FILTER->OUTPUT 순서대로 처리하는데요. 각 단계별로 configuration 파일이 ConfigMap 안에서 나뉘어 있는 것을 볼 수 있습니다.
-
INPUT : 로그 수집 경로와 접미사로 붙일 태그를 정의
-
PARSER : 수집된 로그를 의미 있는 형태로 변환(Parsing)
-
FILTER : 메타 데이터를 추가하거나 불필요한 데이터 필터링
-
OUTPUT : 필터링까지 거친 로그 데이터를 출력하거나 저장 대상 지정
설정을 보면 로그에 붙일 태그에 대한 정규 표현식이 정의되어 있고 최종적으로 특정 태그를 가진 로그를 엘라스틱서치에 저장한다고 설정되어 있습니다. 어떤 OUTPUT 규칙과도 일치하지 않는 로그는 출력되거나 저장되지 않습니다.
저는 샘플 Nginx 로그를 수집하고 처리하기 위해 nginx PARSER와 OUTPUT 규칙을 추가해 봤습니다.
apiVersion: v1
kind: ConfigMap
metadata:
name: fluent-bit-config
namespace: logging
data:
fluent-bit.conf: |
[SERVICE]
Flush 5
Log_Level warn
Daemon off
Parsers_File parsers.conf
@INCLUDE input.conf
@INCLUDE filter.conf
@INCLUDE output.conf
input.conf: |
[INPUT]
Name tail
Tag kube.<namespace_name>.<container_name>.<pod_name>.<docker_id>
Tag_Regex (?<pod_name>[a-z0-9](?:[-a-z0-9]*[a-z0-9])?(?:\\.[a-z0-9]([-a-z0-9]*[a-z0-9])?)*)_(?<namespace_name>[^_]+)_(?<container_name>.+)-(?<docker_id>[a-z0-9]{64})\.log$
Path /var/log/containers/*todo-proxy*.log
Parser nginx
Refresh_Interval 10
parsers.conf: |
[PARSER]
Name kube-tag
Format regex
Regex ^(?<namespace_name>[^_]+)\.(?<container_name>.+)\.(?<pod_name>[a-z0-9](?:[-a-z0-9]*[a-z0-9])?(?:\.[a-z0-9]([-a-z0-9]*[a-z0-9])?)*)\.(?<docker_id>[a-z0-9]{64})$
[PARSER]
Name nginx
Format regex
Regex /^(?<remote>[^ ]*) (?<host>[^ ]*) (?<user>[^ ]*) \[(?<time>[^\]]*)\] "(?<method>\S+)(?: +(?<path>[^\"]*?)(?: +\S*)?)?" (?<code>[^ ]*) (?<size>[^ ]*)(?: "(?<referer>[^\"]*)" "(?<agent>[^\"]*)"(?:\s+(?<http_x_forwarded_for>[^ ]+))?)?$/
Time_Key time
Time_Format %d/%b/%Y:%H:%M:%S %z
filter.conf: |
[FILTER]
Name kubernetes
Match kube.*
Kube_Tag_Prefix kube.
Regex_Parser kube-tag
Merge_Log On
K8S-Logging.Parser On
output.conf: |
[OUTPUT]
Name stdout
Format json_lines
Match kube.*
[OUTPUT]
Name es
Match kube.*
Host elasticsearch
Index todo-fluent-bit
Generate_ID On
플루언트 비트는 본래 IoT와 같은 임베디드 환경에 적합한 경량 플루언트디를 만들기 위해 개발되었고 일반적인 TCP 프로토콜, PostgreSQL DB, Azure 로그 애널리틱스 서비스 등 다양한 플러그인을 지원합니다. 하지만 어디까지나 경량화된 버전이기 때문에 MongoDB나 S3 등 더 다양한 출력 대상을 지원하는 로그 수집기를 찾는다면 FluentD를 사용하는 것이 좋습니다.
Elasticsearch
엘라스틱서치는 Master-Slave 관계를 뚜렷하게 할 수 있는 Statefulset으로 실행합니다. 여기서는 vagrant 공유 디렉토리를 mount하여 파드가 삭제되어도 데이터를 저장할 수 있도록 했는데 실제 운영 환경에서는 클러스터와 스토리지 유형에 따라 영구 볼륨을 생성하고 volumeClaimTemplate를 통해 데이터를 스토리지에 보관할 수 있습니다.
엘라스틱서치는 외부에서 9200 포트로 접근할 수 있고 비록 이번 테스트에는 환경 상 단일 노드로 실행하지만 여러 레플리카로 실행할 경우 9300 포트로 서로 통신합니다.
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: elasticsearch
namespace: logging
labels:
app: sre
spec:
replicas: 1
selector:
matchLabels:
app: es
template:
metadata:
labels:
app: es
spec:
initContainers:
- name: set-data-permission
image: busybox
command: ["sh", "-c", "chown -R 1000:1000 /usr/share/elasticsearch/data"]
securityContext:
privileged: true
volumeMounts:
- name: elasticsearch-persistent-storage
mountPath: /usr/share/elasticsearch/data
containers:
- image: docker.elastic.co/elasticsearch/elasticsearch-oss:7.10.2
name: elasticsearch
ports:
- containerPort: 9200
name: elasticsearch
- containerPort: 9300
name: inter-node
env:
# JVM Heap 메모리 사이즈 설정
- name: ES_JAVA_OPTS
value: "-Xms256m -Xmx256m"
volumeMounts:
- name: es-configs
mountPath: /usr/share/elasticsearch/config/elasticsearch.yml
readOnly: true
subPath: elasticsearch.yml
- name: elasticsearch-persistent-storage
mountPath: /usr/share/elasticsearch/data
volumes:
- name: es-configs
ConfigMap:
name: es-configs
- name: elasticsearch-persistent-storage
hostPath:
path: /vagrant/data
apiVersion: v1
kind: Service
metadata:
name: elasticsearch
namespace: logging
labels:
app: sre
spec:
selector:
app: es
ports:
- name: elasticsearch
port: 9200
targetPort: 9200
type: ClusterIP
단일 노드로 실행하기 때문에 엘라스틱서치에 주입할 설정 파일의 discovery.type 값을 single-node 설정해 주었는데요. 만약 여러 레플리카로 실행하게 된다면 discovery.seed_host에 엘라스틱서치 노드 주소들을, cluster.initial_master_nodes에 마스터로 지정할 노드 hostname을 설정해 주어야 오류를 피할 수 있습니다.
apiVersion: v1
kind: ConfigMap
metadata:
name: es-configs
namespace: logging
labels:
app: sre
data:
elasticsearch.yml: |
cluster.name: "lewisjlee"
discovery.type: single-node
# discovery.seed_host: [엘라스틱서치 노드 주소 list]
# cluster.initial_master_nodes: elasticsearch-0
network.host: 0.0.0.0
Kibana
수집한 로그를 처리하고 저장했다가 UI로 출력할 Kibana를 배치합니다. 로컬 PC에서 vagrant로 생성한 쿠버네티스 클러스터 특성 상 LoadBalancer를 외부로 노출하기 어려워 NodePort로 외부에서 접근할 수 있도록 해줬습니다.
apiVersion: v1
kind: ConfigMap
metadata:
name: kibana-config
namespace: logging
labels:
app: sre
data:
kibana.yml: |
server.host: 0.0.0.0
elasticsearch.hosts: ["http://elasticsearch:9200"]
apiVersion: apps/v1
kind: Deployment
metadata:
name: kibana
namespace: logging
labels:
app: sre
spec:
selector:
matchLabels:
app: kibana
template:
metadata:
labels:
app: kibana
spec:
containers:
- image: docker.elastic.co/kibana/kibana-oss:7.10.2
name: kibana
ports:
- containerPort: 5601
name: kibana
volumeMounts:
- name: kibana-config
mountPath: /usr/share/kibana/config/kibana.yml
readOnly: true
subPath: kibana.yml
volumes:
- name: kibana-config
ConfigMap:
name: kibana-config
apiVersion: v1
kind: Service
metadata:
name: kibana
namespace: logging
labels:
app: sre
spec:
selector:
app: kibana
ports:
- name: kibana
port: 5601
targetPort: 5601
nodePort: 30000
type: NodePort
샘플 애플리케이션에 접속하면 로그가 nginx 파서를 통해 처리되어 지정한 엘라스틱서치 인덱스에 저장되고 Kibana에서 해당 인덱스의 로그를 확인할 수 있습니다. 모든 UI 설정을 마치고 나면 비로소 모든 노드의 애플리케이션 파드에서 생성한 로그를 하나의 화면에서 확인할 수 있게 됩니다.
ELK
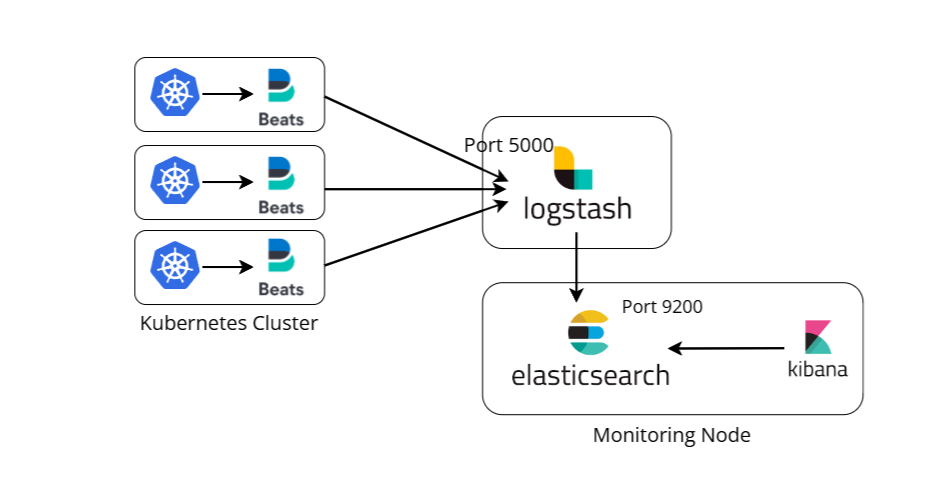
ELK Stack에서는 주로 FileBeat를 사용하여 로그를 수집하고 Logstash를 사용하여 Parsing 및 출력하게 됩니다. 엘라스틱서치와 키바나는 그대로 두고 FileBeat + Logstash가 플루언트 비트처럼 쿠버네티스 메타데이터가 추가된 nginx 로그를 수집하고 처리할 수 있도록 elastic사의 공식 문서를 참고하여 Configuration 해줬습니다.
FileBeat
FileBeat 설정에 processor를 정의하여 쿠버네티스 메타 데이터를 붙일 수 있도록 해주었고 플루언트 비트에서 사용한 ServiceAccount와 RBAC를 동일하게 적용하여 마찬가지로 데몬셋 형태로 실행했습니다.
apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat-config
namespace: logging
labels:
app: sre
data:
filebeat.yml: |
filebeat.inputs:
- type: container
paths:
- /var/log/containers/*todo-proxy*.log
processors:
- add_kubernetes_metadata:
host: ${NODE_NAME}
matchers:
- logs_path:
logs_path: "/var/log/containers/"
output.logstash:
hosts: ["logstash:5000"]
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: filebeat
namespace: logging
labels:
app: sre
spec:
selector:
matchLabels:
app: filebeat
template:
metadata:
labels:
app: filebeat
spec:
ServiceAccountName: log-collector
containers:
- name: filebeat
image: docker.elastic.co/beats/filebeat-oss:7.10.2
volumeMounts:
- name: filebeat-config
mountPath: /usr/share/filebeat/filebeat.yml
readOnly: true
subPath: filebeat.yml
- name: log-dir
mountPath: /var/log
- name: containers-dir
mountPath: /var/lib/docker/containers
readOnly: true
env:
- name: NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
volumes:
- name: filebeat-config
ConfigMap:
name: filebeat-config
- name: log-dir
hostPath:
path: /var/log
- name: containers-dir
hostPath:
path: /var/lib/docker/containers
Logstash
Logstash는 FileBeat에서 수집하고 메타데이터를 얹은 로그를 필터를 통해 파싱합니다. Logstash 공식 문서를 참고하여 로그 메시지를 아파치 로그 형태로 변환하고 중복되거나 불필요한 필드를 제거한 다음 엘라스틱서치에 output하는 파이프라인 설정 파일 ConfigMap을 작성해 주었습니다.
apiVersion: v1
kind: ConfigMap
metadata:
name: logstash-config
namespace: logging
labels:
app: sre
data:
logstash.conf: |
input {
beats {
port => 5000
}
}
filter {
grok {
match => {"message" => "%{COMBINEDAPACHELOG}"}
}
geoip {
source => "clientip"
}
date {
match => [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ]
}
mutate {
remove_field => ["timestamp", "ident", "referrer", "request"]
}
}
output {
elasticsearch {
hosts => ["elasticsearch:9200"]
manage_template => false
index => "todo-logstash"
}
stdout { codec => rubydebug }
}
logstash.yml: |
http.host: "127.0.0.0"
path.config: /usr/share/logstash/pipeline
Logstash 역시 java로 개발된 도구라 어느 정도의 힙 메모리 사이즈를 요구했는데요. 그래서 Logstash를 엘라스틱서치와 같은 노드에 배치하면 노드 메모리 사용률과 LoadAvg가 증가하여 파이프라인 성능에 영향을 줄 수 있습니다. 그래서 매니페스트에 podAntiAffinity를 추가하여 엘라스틱서치와 다른 노드에 파드를 배치하도록 해주었습니다.
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: logging
name: logstash
labels:
app: sre
spec:
selector:
matchLabels:
app: logstash
replicas: 1
template:
metadata:
labels:
app: logstash
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- es
topologyKey: "kubernetes.io/hostname"
containers:
- name: logstash
image: docker.elastic.co/logstash/logstash-oss:7.10.2
ports:
- name: logstash
containerPort: 5000
imagePullPolicy: IfNotPresent # Always, Never
volumeMounts:
- name: logstash-yml
mountPath: /usr/share/logstash/config/logstash.yml
readOnly: true
subPath: logstash.yml
- name: logstash-pipeline
mountPath: /usr/share/logstash/pipeline/logstash.conf
readOnly: true
subPath: logstash.conf
env:
# JVM Heap 메모리 사이즈 설정
- name: LS_JAVA_OPTS
value: "-Xms256m -Xmx256m"
volumes:
- name: logstash-yml
ConfigMap:
name: logstash-config
items:
- key: logstash.yml
path: logstash.yml
- name: logstash-pipeline
ConfigMap:
name: logstash-config
items:
- key: logstash.conf
path: logstash.conf
동일하게 Kibana에서 인덱스 패턴을 생성하면 Logstash로 수집한 로그를 확인할 수 있습니다.
정해진 답은 없다.
이렇게 EFK와 ELK Stack을 직접 구성해 보면서 모든 리소스의 로그를 중앙에서 모니터링할 수 있는 환경의 편리함을 직접 체험해 봤는데요. EFK는 많은 종류의 플러그인을 제공하고 좀 더 가벼운 사양에서 로그를 수집하고 처리할 수 있다는 장점이 있고, ELK는 상대적으로 높은 성능과 복잡도를 요구하지만 모든 도구 스택이 Elastic사에서 개발되어 로그 필터링에 대한 레퍼런스 정보를 더 쉽게 찾아볼 수 있다는 장점이 있는 것 같습니다.
"바퀴를 새로 발명하지 마라"
자동차를 생산하는데 이미 만들어진 좋은 바퀴를 도입해서 사용하면 훨씬 공정이 빨라지겠죠?
FileBeat와 플루언트디(플루언트 비트), Logstash는 개발자의 부담을 줄여줄 수 있는 도구라고 생각됐습니다. 이러한 도구들이 없는 상태에서 중앙화된 로그 모니터링 시스템을 구현한다면 개발자가 직접 로그를 정규 표현식으로 formatting하고 엘라스틱서치에 저장할 수 있는 로직을 직접 구현해야 하죠. 그래서 SRE나 DevOps 조직에서 이러한 도구들을 적극 도입하고 레퍼런스를 참고하여 모니터링 시스템을 대신 구축하고 개발자는 소프트웨어 개발에 더욱 집중할 수 있게 됩니다.
인터넷 검색으로 여러 사례를 찾아보니 서비스 규모나 로그 양에 따라 중간에 kafka나 Amazon kinesis Data Firehose와 같은 도구를 추가할 수도 있고, 필터링 없이 엘라스틱서치에 저장하려고 할 경우 Logstash를 생략하고 FileBeat에서 직접 엘라스틱서치에 output하도록 구성할 수도 있다고 합니다. 그리고 엘라스틱서치를 직접 설치하고 구성하기보다 Opensearch 같은 관리형 서비스를 사용하면 운영 부담을 최소화 할 수도 있고요. 이렇듯 정해진 답은 없고 각자의 환경에서 로그 파이프라인을 구성하고 로그 데이터의 손실이나 지연, 중복이 없으면 그게 곧 정답이라고 여겨집니다.
이번 포스팅에서는 EFK와 ELK를 직접 구성해 보는데 의의를 두었지만 이번 실습을 통해 더 많은 configuration 레퍼런스를 참고하고 엘라스틱서치를 직접 tuning할 수 있도록 깊이 공부해 봐야겠다고 생각하게 되었네요. 이다음에 더욱 가독성 높은 log format과 대용량 처리에 용이한 엘라스틱서치 튜닝을 거쳐 고도화한 로그 처리 파이프라인에 대해 포스팅하게 될 날이 오기를 내심 기대해 봅니다 :)
로그 수집기 파드에 대한 보안 꼭 신경쓰기
실제 운영 환경에서는 애플리케이션 로그 뿐만 아니라 message나 syslog 같은 시스템 로그를 처리하는 파이프라인도 구성할 수 있습니다. 앞의 플루언트 비트와 FileBeat 데몬셋을 살펴보면 모든 로그를 수집하고 처리한다고 가정하고 로그 디렉토리를 통째로 mount한 것을 볼 수 있는데요. 즉 로그 수집기 파드에 접근할 수 있는 사용자라면 누구나 시스템의 모든 로그를 확인할 수 있다는 것을 의미합니다. 그래서 반드시 권한을 가진 사용자만 로그 수집기 파드에 접근할 수 있도록 사용자 접근 제어가 꼭 필요합니다. 그리고 로그 수집기 파드가 파드명과 네임스페이스 등 메타데이터를 수집해서 붙일 경우 꼭 필요한 권한만 가질 수 있도록 ServiceAccount와 RBAC 설정이 꼭 필요합니다.
References
Elton Stoneman. (2021). 쿠버네티스 교과서. 길벗출판사
YAML Configuration from Fluent Bit: Official Manual
Container input, Filebeat Reference [7.10] from Elastic
Filter plugins, Logstash Reference [7.10] from Elastic
Add Kubernetes metadata, Filebeat Reference [7.10] from Elastic
댓글남기기