초기 2-tier에서 3-tier Architecture로의 전환 여정
초기 프로젝트를 진행할 때는 불필요한 비용과 오버 엔지니어링을 방지하기 위해 서비스 규모와 SLO(Service Level Objective)를 적절하게 예측해야 합니다. 이미 대중에 널리 알려진 브랜드 IP를 보유한 회사가 새로운 프로젝트를 할 경우 초기부터 많은 트래픽이 발생할 것을 대비하여 상대적으로 높은 사양의 인프라를 초기 구축해야 하지만 그렇지 않을 경우 단순한 구조로 시작하여 점차 아키텍쳐 구조를 바꿔볼 수 있습니다.
본 포스팅에서는 제가 임대형 웹 쇼핑몰 서비스의 인프라 운영을 담당하면서 호스팅 사이트와 활성 사용자 수 증가에 따라 초기 2-tier Architecture에서 3-tier Architecture까지 전환한 경험에 대해서 소개해 드리려고 합니다.
초기 2-tier 구성
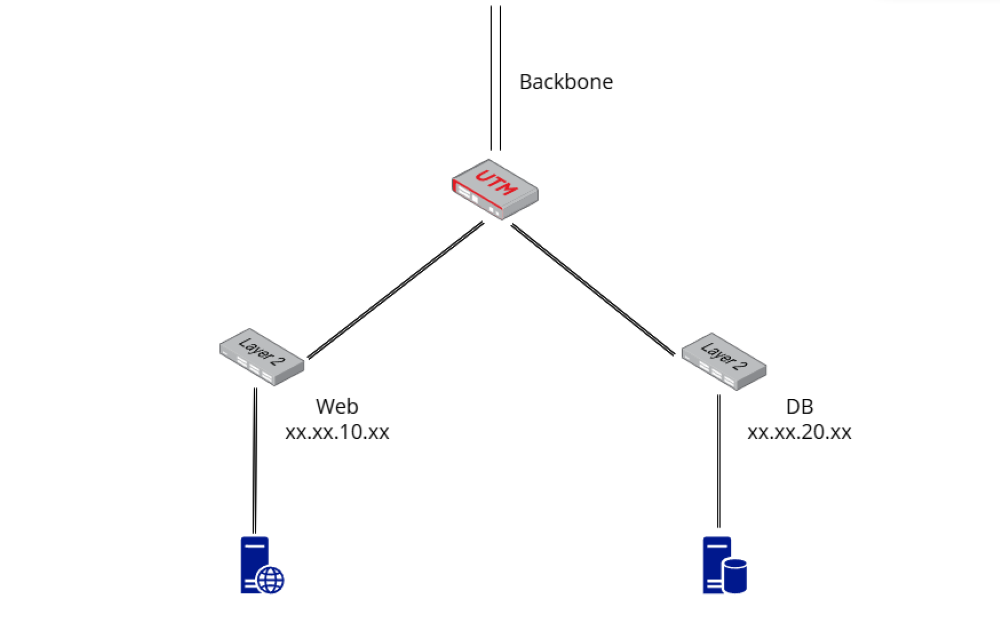
웹 서버 - DB 서버로 구성된 2-tier 아키텍쳐입니다. WEB 대역과 DB 대역이 별도의 LAN으로 분리되어 있고, 라우팅 및 방화벽 정책을 UTM이라고 하는 장비에서 중앙 관리합니다. 사용자 100 ~ 1000명 정도의 여러 개인 혹은 소규모의 쇼핑몰 사이트들을 호스팅하기 때문에 1 ~ 2TB 용량의 데이터베이스 한 대에 모든 데이터를 저장하되, 사이트 아이디인 서브 도메인과 고객명, 상품명 등 컬럼을 키로 지정하고 인덱스 또한 적절하게 설정해 주었습니다.
또한 그림에는 나오지 않았지만 쇼핑몰 이미지와 DB 데이터를 백업하기 위한 백업 서버 또한 배치했습니다. 모니터링 또한 빼놓을 수 없는 부분이기 때문에 Glances + InfluxDB + Grafana 스택의 모니터링 시스템을 구축하였습니다.
Load Balancer 및 Redis 도입
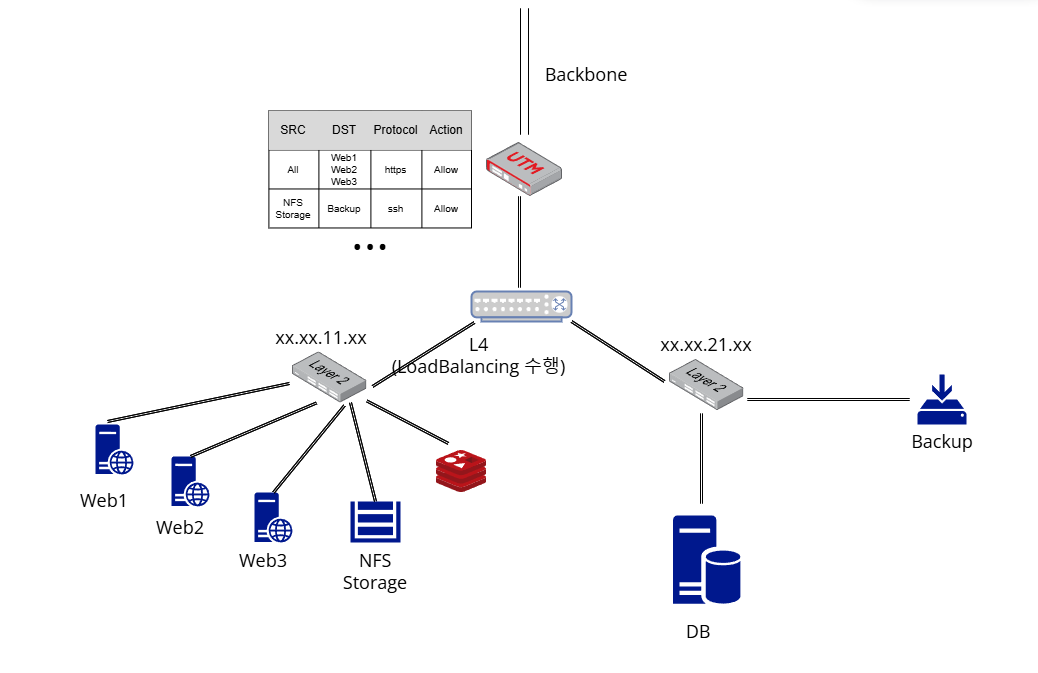
여러 소규모 쇼핑몰 사이트들을 호스팅한다는 것은 결국 하나의 중규모 서비스를 운영하는 것과 마찬가지이기 때문에 안정성을 한층 개선한 구조의 Architecture가 필요했습니다. 그래서 사이트들에 유입되는 트래픽을 여러 대의 서버에 분산하고 이 중 한 대에 장애가 발생하더라도 중단 없이 다른 서버들에 forward할 수 있도록 L4 LoadBalancer를 도입하였습니다. 그리고 반복적으로 요청되는 데이터를 cache하기 위해 Redis를 도입하고 분산된 서버에서 이미지 데이터를 저장하고 불러올 수 있도록 NFS 서버를 같은 서브넷에 설치하였습니다.
서버 Scale up 및 수량 최적화로 안정적인 운영과 비용 절감
기존의 CentOS7가 EOS를 앞두고 있어 최신 버그/보안 패치를 적용할 수 있는 신규 Downstream OS인 Rocky Linux로의 이전이 필요했습니다. 그래서 팀 내부적으로 신규 OS로 전환하면서 동시에 memory 크기와 CPU core 수를 Scale up한 서버로 사이트 도메인을 하나씩 이전하여 늘어나는 사이트와 사용자 트래픽도 함께 대비하는 것으로 의견을 모았습니다.
이처럼 시스템 사양을 높이고 서버 대수를 줄인 덕분에 IDC 여유 공간을 25% 확보하여 운영 비용을 절감할 수 있었습니다.
네트워크 트래픽 최적화에 대한 고민
앞선 방법들을 통해 시스템 아키텍쳐를 꾸준히 개선하며 트래픽 증가에 대응해 왔지만 여전히 특정 사이트에서 이벤트 진행 시 DB Slow Query와 Timeout이 일부 발생하고 트래픽 사용량이 최대 500MB/s까지 웃돌기도 했습니다. 그래서 이 문제를 기존 2-tier 아키텍쳐에서 웹 서버가 외부 HTTP 트래픽과 데이터베이스 트래픽을 동일한 물리 회선으로 처리하기 때문에 요청이 증가하면서 네트워크 대역폭 포화와 병목이 발생하는 것으로 접근했는데요. 그래서 웹 트래픽과 DB 트래픽을 서로 다른 회선으로 분리해서 처리하는 방안을 고민하게 되었습니다.
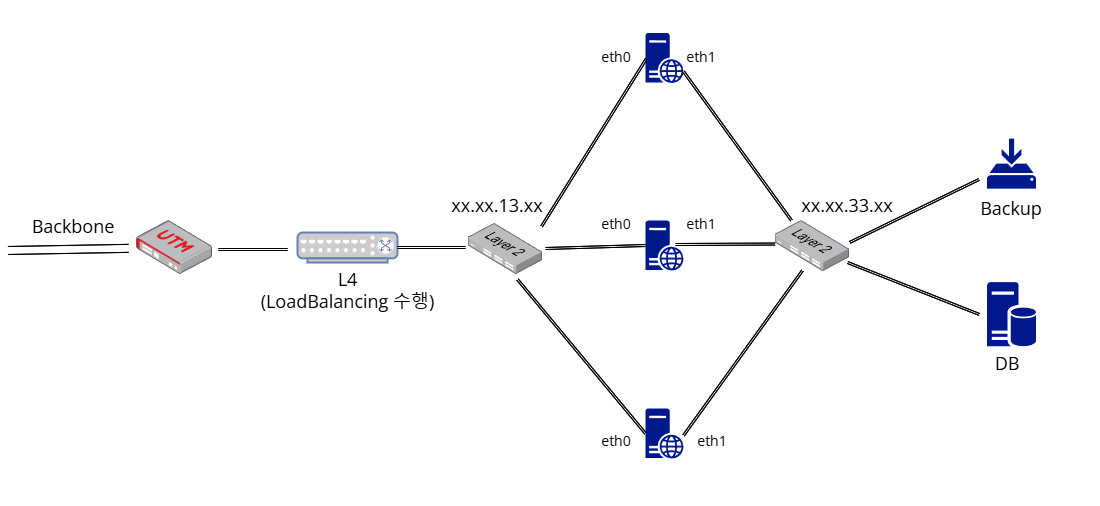
처음 생각했던 방안은 그림과 같습니다. 웹 서버에 두개의 이더넷에 회선을 연결하여 하나는 외부 http(s) 트래픽을 처리하고 다른 하나는 데이터베이스에 연결하는 방식입니다. 그림대로 물리적 인프라를 구축하고 DB 트래픽이 eth1 회선을 타도록 라우팅 테이블을 구성한 다음, telnet을 이용하여 라우팅 및 mysql 연결을 테스트했습니다. 이제 실제 서비스 테스트와 운영 환경에 적용만 하면 된다고 생각했는데 또 하나 고려해야 할 부분이 생겼습니다.
앞단에서 데이터베이스에 직접 접근할 수 있다고?
당시 ISMS 인증 심사 대비 컨설팅을 함께 받고 있었는데, 맨 앞단의 웹 서버가 데이터베이스에 직접 접근할 수 있는 구조가 보안 취약점으로 평가될 수 있다는 점을 전달받았습니다. 방화벽을 UTM과 서버 firewalld를 통해 이중으로 설정해 두고 있었지만 명시된 인증 요건을 달성하기 위해 데이터베이스에 접근할 수 있는 애플리케이션 레이어를 따로 분리하기로 결정했습니다.
3-tier Architecture
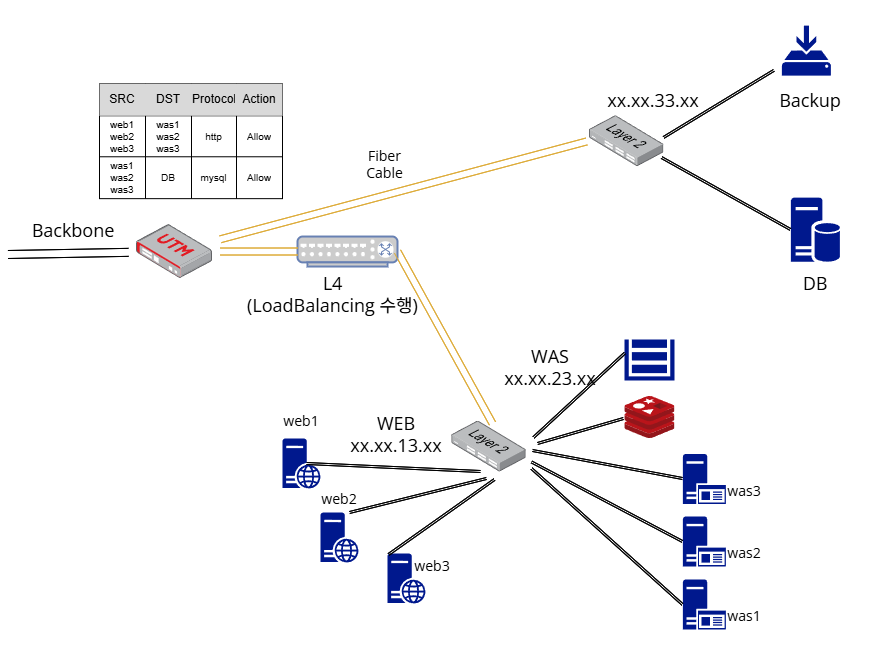
그림처럼 데이터베이스와 Backup 서버가 있는 서브넷을 별도로 구성하고, L4와 연결된 스위치 아래 두 개의 VLAN으로 WEB과 WAS tier를 분리합니다. WAS tier에 NFS Storage와 Redis를 함께 배치하고 UTM과 firewalld 방화벽을 통해 꼭 필요한 허용 정책만을 설정해 줍니다. 그리고 외부 트래픽의 전달과 데이터베이스로의 트래픽 전달 속도를 개선하기 위해 UTM과 데이터베이스 서브넷, L4 그리고 WEB/WAS tier의 L4와 L2 사이의 구간을 광케이블로 연결해 주었습니다.
그리고 웹 서버가 WAS에 요청을 upstream할 수 있도록 nginx에 ‘proxy_pass’ 구문의 location을 추가했고, sticky session이 적용되도록 ‘ip_hash’ 를 설정했습니다. 이렇게 되면 웹 서버는 애플리케이션과 완전히 분리되어 프록시의 역할만 수행하게 됩니다.
location ~ \.php {
proxy_pass http://backend;
}
upstream backend {
ip_hash;
server was1:80;
server was2:80;
server was3:80;
}
WEB Layer는 외부 http 요청만을, WAS Layer는 백엔드만 처리하여 시스템 부담을 대폭 완화할 수 있는 3-tier 아키텍쳐의 장점을 몸소 체감할 수 있었습니다. Grafana를 통해 확인한 서버 당 네트워크 트래픽 사용량이 전반적으로 60% 절감되었을 뿐만 아니라 이벤트 시 Slow Query 발생이 80% 감소했고 Timeout은 전혀 발생하지 않았습니다.
이미 대부분의 서버 사양이 최대 트래픽에 맞춰 산정되어 있었던 덕분에 시스템 부하 관련 문제는 없었지만, nginx와 php 애플리케이션 워크로드를 서로 다른 tier로 분리하는 방식은 서버가 특정 워크로드에만 시스템 자원을 사용하게 하여 부하를 완화하고 장애 발생 시 어떤 워크로드에서 발생했는지 명확하게 파악하고 신속하게 대응할 수 있도록 하는 등 다양한 긍정적인 효과를 경험할 수 있습니다.
더욱 성능이 좋은 Architecture를 만들기 위해서는
위의 작업들을 거치면서 Redis, Load Balancing, 3-tier Architecture 등 서비스 인프라 성능 개선을 위한 다양한 기술적 구조와 노하우들을 경험할 수 있었습니다. 하지만 더 많은 방법들을 생각하고 실행에 옮기지 못한 것에 대한 아쉬움도 느꼈는데요. On-Premise 인프라 특성 상 자원을 손쉽게 scale out할 수 없어 처음부터 최대 트래픽을 고려한 설계를 해야 했고, 이중화하지 않은 데이터베이스를 포함하여 재해 복구 방안을 Backup & Restore 방식에만 의존하다 보니 상당한 시스템 Downtime이 비교적 오래 발생할 우려 또한 있었습니다. 더욱 신뢰성 높은 서비스 인프라를 구축하기 위해서는 더 효율적인 여러가지 방식들을 알고 적용할 수 있어야 합니다.
퍼블릭 클라우드로의 이전
AWS, GCP, Azure 등 퍼블릭 클라우드 환경으로 이전하면 손쉬운 서버 scale out이 가능하기 때문에 처음부터 대형 자원을 선정할 필요가 없습니다. 평상시의 트래픽을 소화할 수 있는 최소한의 자원을 운용하다가 피크 타임에 동일한 자원을 프로비저닝하는 Auto Scaling 정책을 생성할 수 있죠. 또한 퍼블릭 클라우드 서비스는 EFS, S3와 같이 무제한에 가깝게 확장할 수 있는 스토리지 서비스와 RDS, Aurora, ElastiCache 같은 데이터베이스 서비스, CloudFront 같은 CDN 서비스를 제공하고, 서버리스 Lambda나 API Gateway, 특정 레이어에서 장애가 확산되지 않도록 도입할 수 있는 SQS 같은 큐 서비스 등 없는 게 없을 정도로 많고 다양한 관리형 서비스를 제공하기 때문에 높은 생산성을 위해 이제는 사용하지 않을 수가 없다고 생각됩니다.
PG 혹은 금융 관련 서비스의 경우 데이터 거버넌스나 규정 준수 문제에 부딪혀 클라우드로의 이전이 어려울 수 있습니다. 이럴 경우 프론트엔드나 다른 민감하지 않은 마이크로 서비스만 클라우드로 이전하고 퍼블릭 클라우드와 온프레미스 환경을 상호 연결한 하이브리드 클라우드 환경을 고려해볼 수 있습니다.
IaC 기반 인프라 형상 관리
이전에는 Shell Script를 통해 서버 환경을 빠르게 구성하였지만 멱등성을 보장하지 못한다는 점에서 한계가 있다고 생각했습니다. 그래서 IaC를 고려하게 되었는데, 대표적으로 terraform과 ansible이 언급됩니다. 이러한 IaC 도구를 사용하면 작성한 코드대로 서비스 인프라를 휴먼 에러 없이 프로비저닝하고 원하는 미들웨어나 서버 구성까지 한번에 할 수 있다는 장점이 있습니다. 여러 차례 반복 실행해도 특별한 변경 사항이 없다면 처음에 의도한 대로 인프라를 유지할 수 있죠. 이러한 코드와 state 파일은 Github와 같은 레포지토리에 저장하고 여러 사람과 공유할 수 있습니다.
컨테이너 도입
애플리케이션과 의존성 파일을 하나의 컨테이너 이미지로 빌드하여 배포할 수 있습니다. 여러 대의 서버를 직접 일일이 구성하다 보면 굉장히 번거로울 뿐더러 빌드가 잘못되거나 의존성이 누락될 수있는 단점이 있는데요. 이를 컨테이너 이미지로 묶어서 보관하였다가 새로운 시스템을 프로비저닝하면 해당 이미지를 pull한 다음 컨테이너로 배치하면 더욱 빠르고 정확하게 서버를 구성할 수 있습니다. 각각의 컨테이너는 서로 다른 네임스페이스로 격리되어 특정 워크로드의 장애가 다른 워크로드나 노드에 영향을 미치지 않습니다.
대표적인 컨테이너 런타임에는 Docker가 있고, Docker로 생성한 이미지를 갖고 containerd나 cri-o등 다른 컨테이너 런타임에서 컨테이너를 실행하고 오케스트레이션할 수 있는 쿠버네티스를 도입해볼 수 있습니다. 하지만 쿠버네티스는 많은 학습량을 요구하는 데다 대규모 클러스터에 서비스를 효율적으로 분산하는데 주 목적을 두는 기술이므로 자칫 잘못 도입하게 되면 운영 관리가 어려운 오버엔지니어링이 될 수 있습니다. 중소 규모의 프로젝트에서는 이러한 오케스트레이션 기능 없이 Docker만 도입해도 충분한 효과를 볼 수 있습니다.
컨테이너 기술을 사용하게 되면 성능 Metric 수집을 서버 수준에서만 할 수 있는 glance가 아닌 Prometheus를 사용하여 노드 뿐만 아니라 파드와 컨테이너 단위로도 Metric을 수집하여 모니터링할 수 있습니다.
댓글남기기