시스템 상태 체크 명령어 top 톺아보기(Feat. LoadAvg)
top은 시스템 성능에 이슈가 생겼을 때 가장 먼저 확인해볼 수 있는 명령어 입니다. 저 또한 리눅스 서버를 운영하면서 성능 저하가 일어났을 때 주로 top을 사용해서 시스템 상태를 확인했는데요. 최근에는 zabbix나 grafana와 같은 모니터링 도구가 많이 발달하여 LoadAvg나 Memory Usage 정도는 직접 서버에 접속하지 않고도 확인할 수 있지만, 서버에서 직접 명령어를 실행하여 모니터링 시스템보다 더 많은 정보를 획득해 볼 수도 있습니다.
그럼 시스템 전반의 상태를 가장 빠르게 확인해볼 수 있는 top에 대해 하나씩 살펴보겠습니다.
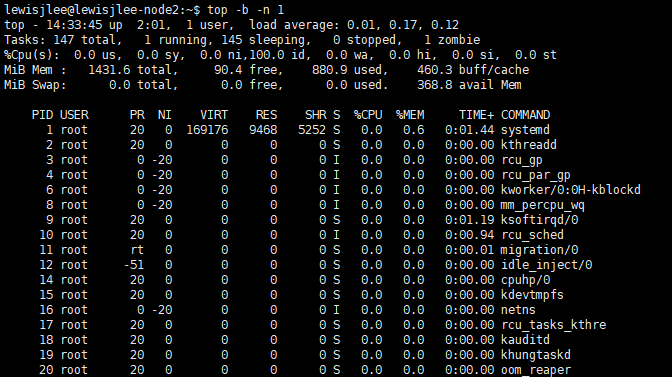
로컬에서 실행한 VM에서 top을 실행한 결과입니다. 아무 옵션을 주지 않고 실행하면 3초 간격으로 시스템 상태 정보를 갱신하여 출력하고, 이미지과 같이 옵션을 주어 실행하면 시스템 자원을 계속 소비하지 않고 현재의 시스템 상태만 빠르게 출력하고 빠져나옵니다.
top에서는 기본적으로 다음 정보들을 확인할 수 있습니다.
-
현재 서버의 시간과 서버가 구동된 시간
-
몇 명의 사용자가 로그인해 있는지
-
LoadAvg
-
현재 시스템에서 구동 중인 프로세스의 수
-
CPU, Mem, Swap 사용량
항목별 의미
top을 실행하면 PID와 user 뿐만 아니라 PR, NI 등 다양한 항목들을 확인할 수 있는데요. 각 항목은 다음의 의미를 갖고 있습니다.
-
PR - 프로세스의 실행 우선 순위, 즉 다른 프로세스들보다 먼저 실행되어야 하는지의 여부(기본값 20)
- rt - RT(RealTime) 스케줄러에 의해 실행되며, 일반적인 사용자가 생성한 프로세스가 아닌, 커널 데몬과 같이 반드시 특정 시간 안에 종료되어야 하는 중요한 프로세스. 이러한 프로세스들은 일반적인 스케줄러보다 더 먼저 실행되어 시스템의 안정적인 운영을 보장한다.
-
NI - PR 기본값을 얼마나 조정할 것인가를 나타내는 값, PR 기본값 + NI 값이 프로세스 최종 우선 순위로서 PR에 매겨지며, 값이 낮을수록 우선 순위를 띤다.
-
VIRT - 프로세스에 할당(Commit)된 가상 메모리의 크기
-
RES - VIRT 중 실제로 프로세스가 물리 메모리에 올려서 사용하고 있는 크기
-
SHR - 다른 프로세스와 공유하고 있는 메모리의 크기
-
S - 프로세스의 상태
각 CPU Core의 실행 큐(Run Queue)에는 우선순위 별로 프로세스가 적재되는데요. 서버에서 실행하는 대부분의 프로세스들이 처음 부여받는 기본값 20에 NI 값을 더한 최종 우선 순위 값이 PR에 매겨지게 됩니다. 기준으로 값이 낮을수록 우선적으로 CPU를 스케줄링받게 됩니다.
nice명령어를 통해 NI 값을 지정하여 우선 순위를 조정하여 프로세스를 실행할 수 있고, renice 명령어를 통해 실행 중인 프로세스의 NI 값을 조정하여 우선 순위를 조정할 수 있습니다.
sudo nice -n 10 myscript.sh # 우선 순위를 10만큼 늦춰서 실행
sudo nice -n -5 myscript.sh # 우선 순위를 -5만큼 빠르게 조정하여 실행
sudo renice -20 -p 1234 # PID 1234의 프로세스 우선 순위를 -20만큼 빠르게 조정
sudo renice 5 -u lewisjlee # lewisjlee 사용자의 프로세스 우선 순위를 5만큼 늦추기
Memory Commit이란?
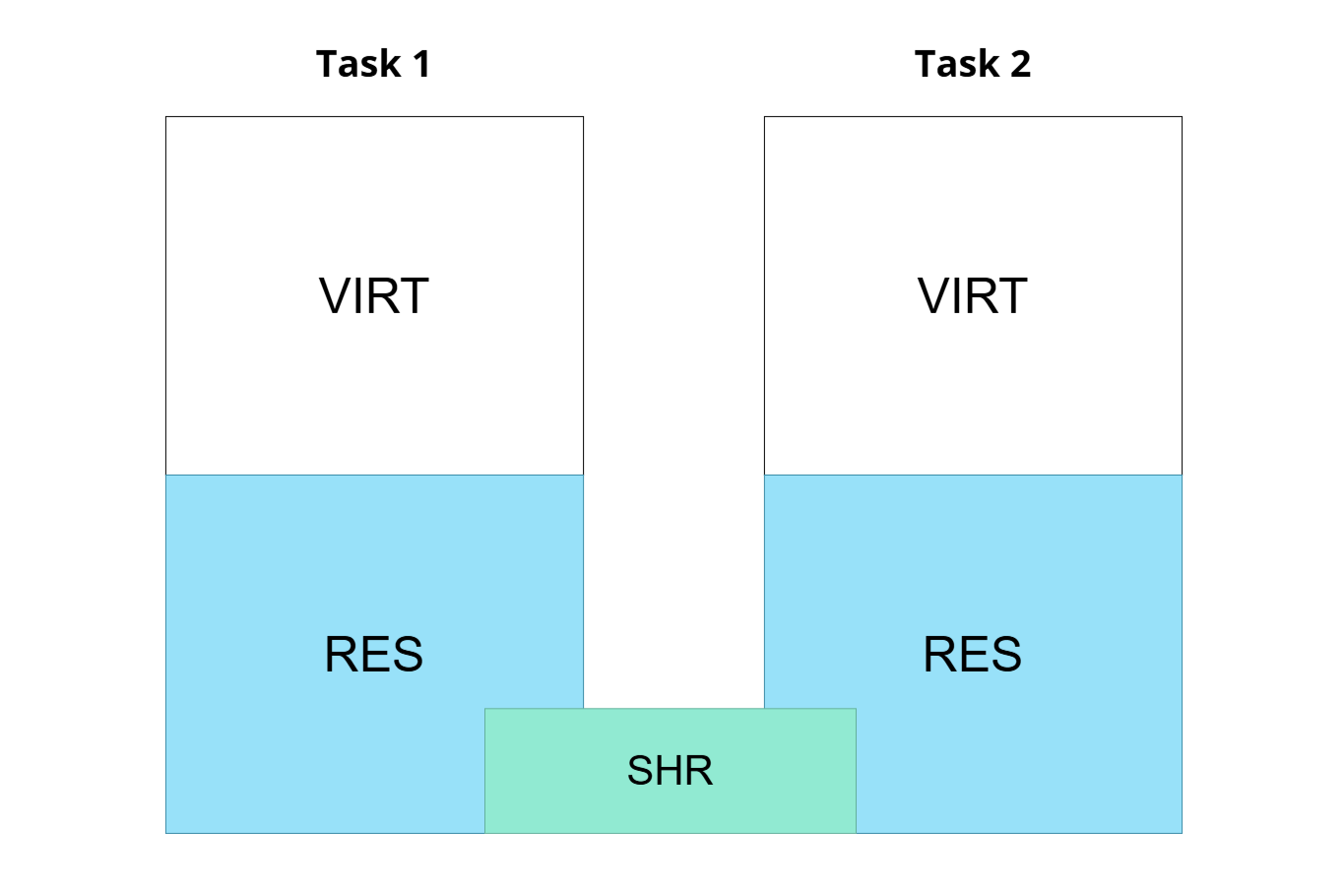
VIRT, RES, SHR는 프로세스에 대한 메모리 Commit 및 사용과 관련된 항목입니다.
프로세스가 커널에 필요한 만큼의 메모리를 요청하면 커널은 프로세스에 사용 가능한 가상 메모리 영역을 주고, 실제로 할당은 하지 않으나 해당 영역을 프로세스에 주었다는 것을 저장합니다. 이것을 Memory Commit이라고 합니다.
Memory Commit이 일어난 후 프로세스는 할당받은 가상 메모리 영역에 쓰기 작업을 수행하게 되는데요. 가상 메모리 영역은 실제 물리 메모리 공간이 아니기 때문에 이 때 Page fault가 발생하게 됩니다. Page fault가 발생하면 그 때 커널은 실제 물리 메모리 공간에 할당한 가상 메모리 영역을 mapping하여 물리 메모리를 사용하게 합니다.
SHR는 다른 프로세스와 공유하는 공유 메모리 크기를 나타냅니다. 주로 라이브러리가 공유 메모리에 올려져 사용되는데요. 일례로 대부분의 리눅스 자체 프로세스는 glibc라는 라이브러리를 참조하는데, 이러한 라이브러리를 각 프로세스의 독립된 메모리 공간에 올려 사용하게 되면 OS를 구동하는 데도 메모리 사용량이 굉장히 높아지게 됩니다. 따라서 다수의 프로세스가 사용하는 라이브러리의 경우 주로 공유 메모리에 올려 사용합니다.
S : 프로세스 실행 상태
top에서 프로세스 실행 상태를 나타내는 S는 다음과 같이 상태를 나타냅니다.
-
R - CPU 실행 큐(Run Queue)에서 실제로 CPU 자원을 소모하고 있는 프로세스
-
D - Uninterruptible sleep, 원래는 R 상태였다가 실행 큐를 빠져나와 대기 큐에 들어가 디스크 혹은 네트워크 I/O를 대기하고 있는 상태
-
S - Interruptible sleep, 시스템 리소스를 사용하고 있지 않지만 언제든 리소스를 요청하여 사용할 수 있는 상태(e.g. sleep() 혹은 콘솔 입력을 기다리는 경우)
-
T - Traced or Stopped, strace와 같이 프로세스의 시스템 콜을 추적하고 있는 상태
-
Z - 좀비 프로세스
좀비 프로세스
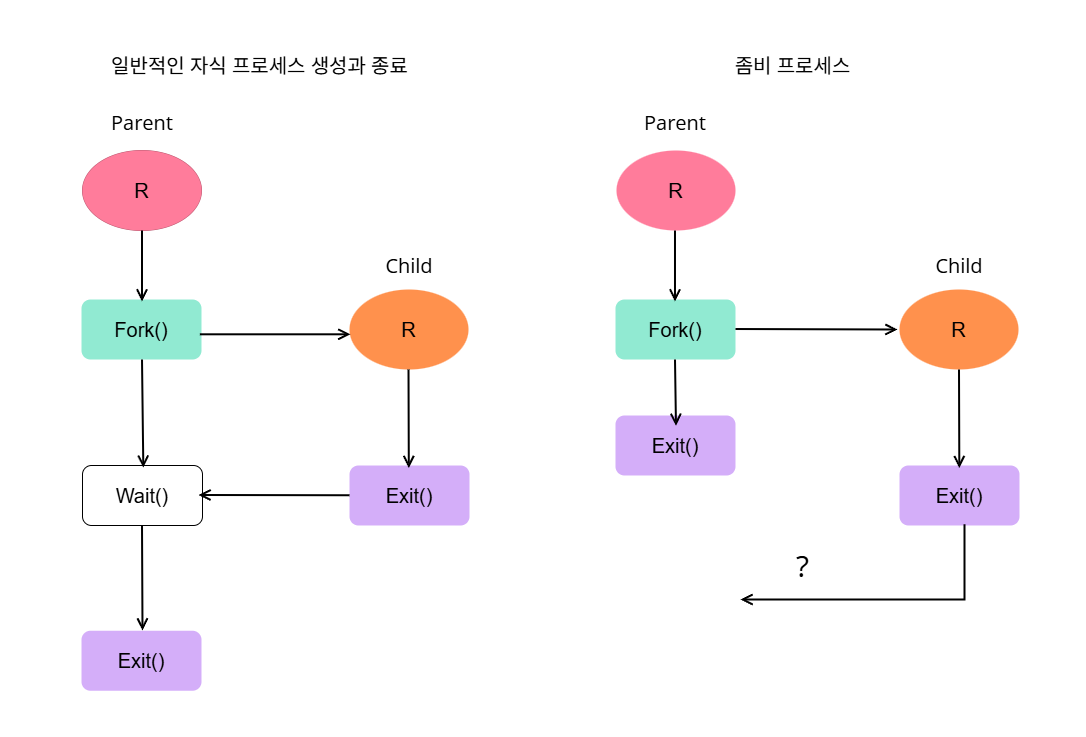
좀비 프로세스는 부모(Parent) 프로세스가 죽은 자식(Child) 프로세스를 의미합니다.
부모 프로세스는 fork() 시스템 콜을 통해 자식 프로세스를 생성하고 wait() 상태에 들어갑니다. 그동안 자식 프로세스가 동작을 마친 후 종료할 때 wait() 상태의 부모 프로세스에 종료되었음을 알립니다.
하지만 만약 자식 프로세스가 종료하기도 전에 부모 프로세스가 먼저 종료되면 어떻게 될까요? 자식 프로세스는 종료되었음을 알려줄 곳이 없어 좀비 상태로 남게 됩니다. 이것을 좀비 프로세스라고 합니다.
좀비 프로세스는 종료 상태이기 때문에 시스템 자원을 사용하지 않습니다. 하지만 정상 종료 상태가 아니기 때문에 여전히 PID를 점유하고 있죠. 그래서 부모 프로세스가 자식 프로세스보다 먼저 종료되어 좀비 프로세스가 많아지게 되면 새로운 프로세스에 할당할 PID가 고갈되어 새로운 프로세스 실행에 문제가 될 수 있습니다.
시스템에서 사용할 수 있는 최대 PID는 아래 명령어로 확인할 수 있습니다.
sudo sysctl -a | grep pid_max
LoadAvg, 정확히 무엇일까?
저는 이전에 LoadAvg를 얼마나 많은 프로세스가 CPU를 사용하려고 하는지에 대한 값이라고 생각하고 높으면 높을수록 시스템에 많은 부하가 있는 것이라고 이해하곤 했는데요. 어떻게 보면 맞는 이야기처럼 보일 수 있겠지만 참고 자료를 접하면서 제가 기존에 알던 것만으론 LoadAvg를 완벽하게 표현하기 어렵다는 생각이 들었습니다. 그렇다면 LoadAvg는 정확히 무엇일까요?
앞서 top에서 출력되는 항목 중 S는 프로세스의 상태를 나타낸다고 했는데요. LoadAvg는 그 중에서도 R이나 D 상태에 있는 프로세스 수의 1, 5, 15분동안의 평균값을 의미합니다. 그래서 값이 높을수록 CPU를 사용하는 프로세스가 많다고 할 수 있지만 시스템이 얼마나 많은 CPU 코어를 보유하고 있느냐에 따라 해석이 달라지게 됩니다.
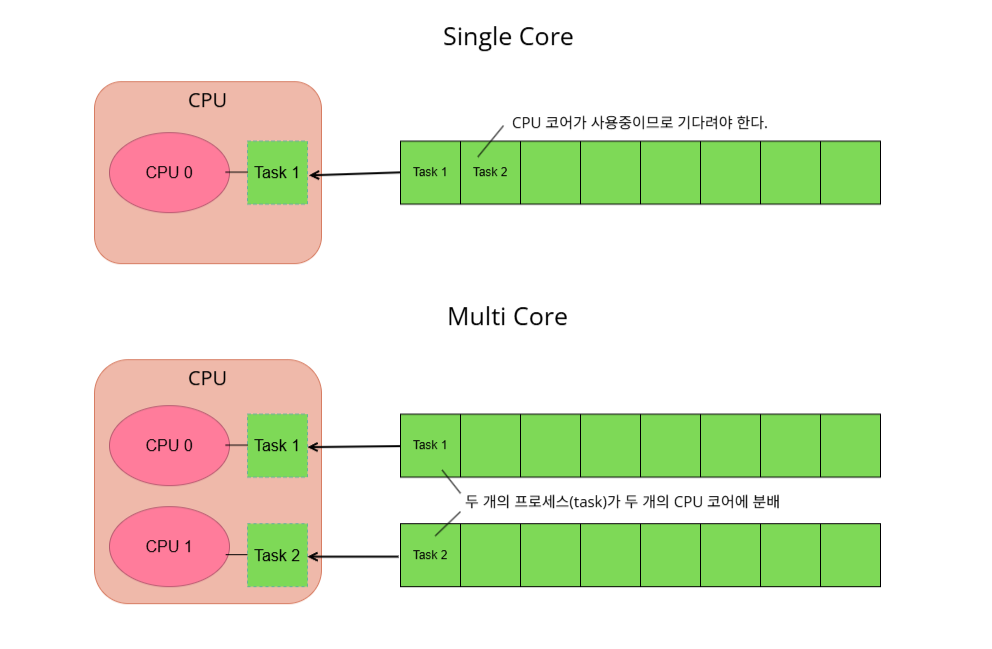
예를 들어 현재 LoadAvg가 2이라고 할 때 시스템에 CPU 코어가 1개뿐이라면 하나의 실행 큐에 2개의 프로세스가 쌓이게 되고 CPU 코어는 한 번에 1개만 처리할 수 있기 때문에 나머지 하나의 프로세스는 대기하게 됩니다. 즉 현재 시스템이 처리할 수 있는 프로세스보다 조금 더 많은 프로세스가 있어 이 경우 부하가 높다고 할 수 있습니다.
반면 CPU 코어가 2개라면 각각의 프로세스가 서로 다른 CPU 코어의 실행 큐에 쌓이고 1개씩 처리되기 때문에 기다려야 하는 프로세스가 없게 됩니다. 이 경우에는 현재 시스템이 처리할 수 있는 만큼의 프로세스가 있다고 할 수 있습니다.
top으로 확인할 수 있는 정보 중에서도 LoadAvg만 빠르게 확인하고 싶을 땐 uptime이라는 명령어를 실행해볼 수 있습니다.
uptime
시스템에 어떤 부하가 있는지 알려면?
앞선 내용을 통해 R 상태는 CPU 실행 큐에서 CPU를 소비하고 있는 프로세스를 의미하고 D 상태는 일시적으로 실행 큐를 빠져나와 I/O를 대기하고 있는 프로세스임을 알 수 있었고, 이러한 R 혹은 D 상태의 프로세스 수의 평균값이 LoadAvg임을 알 수 있었습니다. 그렇다면 LoadAvg를 통해 확인한 시스템 부하가 어떤 상태의 프로세스들에 의해 발생하는지 어떻게 알 수 있을까요?
vmstat는 프로세스와 메모리, Swap, I/O, CPU의 현재 상태를 실시간으로 확인할 수 있는 명령어로, 현재 실행되는 프로세스가 CPU를 사용 중인 프로세스인지(R) 아니면 I/O를 대기하고 있는 상태인지(D) 확인할 수 있습니다.
vmstat 1
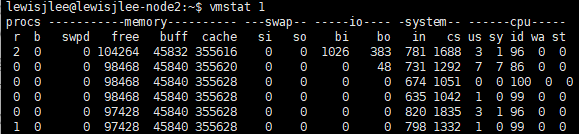
맨 앞의 proc 항목 아래 r과 b로 열이 나눠진 것을 확인할 수 있는데요. 각 열은 다음을 의미합니다.
-
r - CPU 자원을 사용하는 CPU Bound 프로세스
-
b - I/O를 위해 대기 큐에 있는 I/O Bound 프로세스
즉 r은 R 상태의 프로세스의 수, b는 D 상태의 프로세스의 수를 의미하게 됩니다. 어떠한 이슈로 시스템 부하가 증가했다면 vmstat를 실행하여 어떤 유형의 프로세스가 주로 부하를 일으키는지 확인해볼 수 있죠. 특히 b 의 값이 높을 경우 LoadAvg가 낮은 수준이더라도 지속적으로 I/O를 발생시키고 있는 것을 의미하기 때문에 시스템의 성능에 문제가 될 수 있습니다. 이럴 경우 전체적인 I/O 처리 과정에 문제가 있지 않은지 살펴볼 필요가 있습니다.
CPU Bound 혹은 I/O Bound 프로세스의 수는 /proc/sched_debug의 nr_running, nr_uninterruptible 항목에서도 각각 확인해볼 수 있습니다.
마치며
시스템 엔지니어로 근무하면서 top을 통해 LoadAvg와 메모리 사용율, Disk I/O 등의 성능 지표를 주로 살펴봤지만 자세한 원리와 이론을 알지 못한 채 시스템 이슈를 두루뭉술하게 진단했던 적이 꽤나 많았던 것 같습니다. DevOps나 SE로서 중요한 역할 중 하나는 시스템에 문제가 발생했을 때 깊이 있는 영역에서 원인을 자세하고 명확하게 파악하고 공유하는 것인데 그러한 역할을 제대로 수행하지 못했던 적이 있었죠. 이번에 참고 자료를 읽으며 top에서 보여주는 정보들과 LoadAvg 계산 원리, 프로세스 진단에 대해 더욱 면밀하게 이해할 수 있게 되어 앞으로는 더욱 전문적인 엔지니어 다운 모습을 보일 수 있다는 자신감과 깊이 있는 영역에 대한 더 많은 공부 의지를 가질 수 있었습니다.
References
강진우. (2017). DevOps와 SE를 위한 리눅스 커널 이야기. 인사이트
댓글남기기